IBM Watson Data Platform
Big data governance for industrial-scale machine learning, data science and predictive analytics.
Introduction
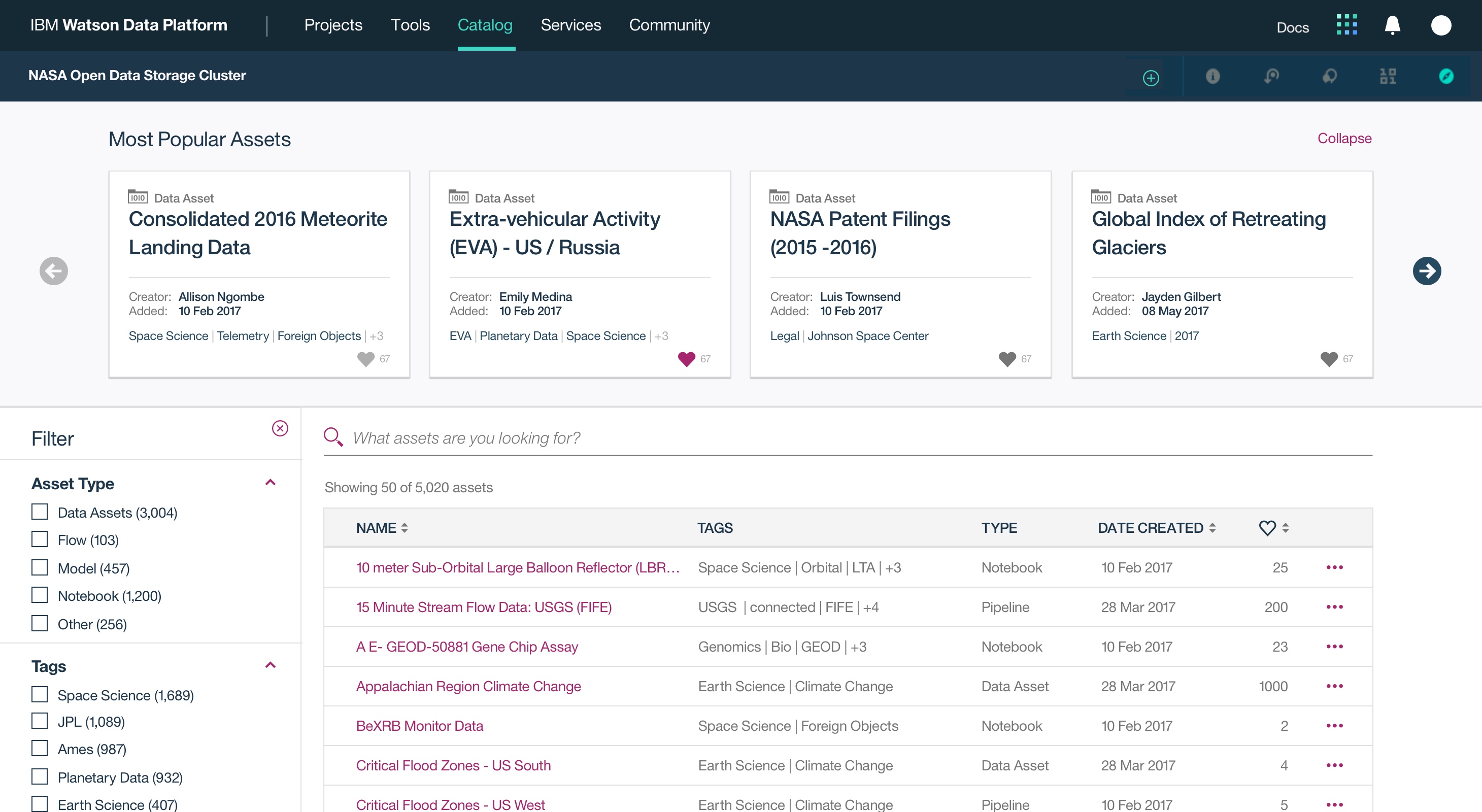
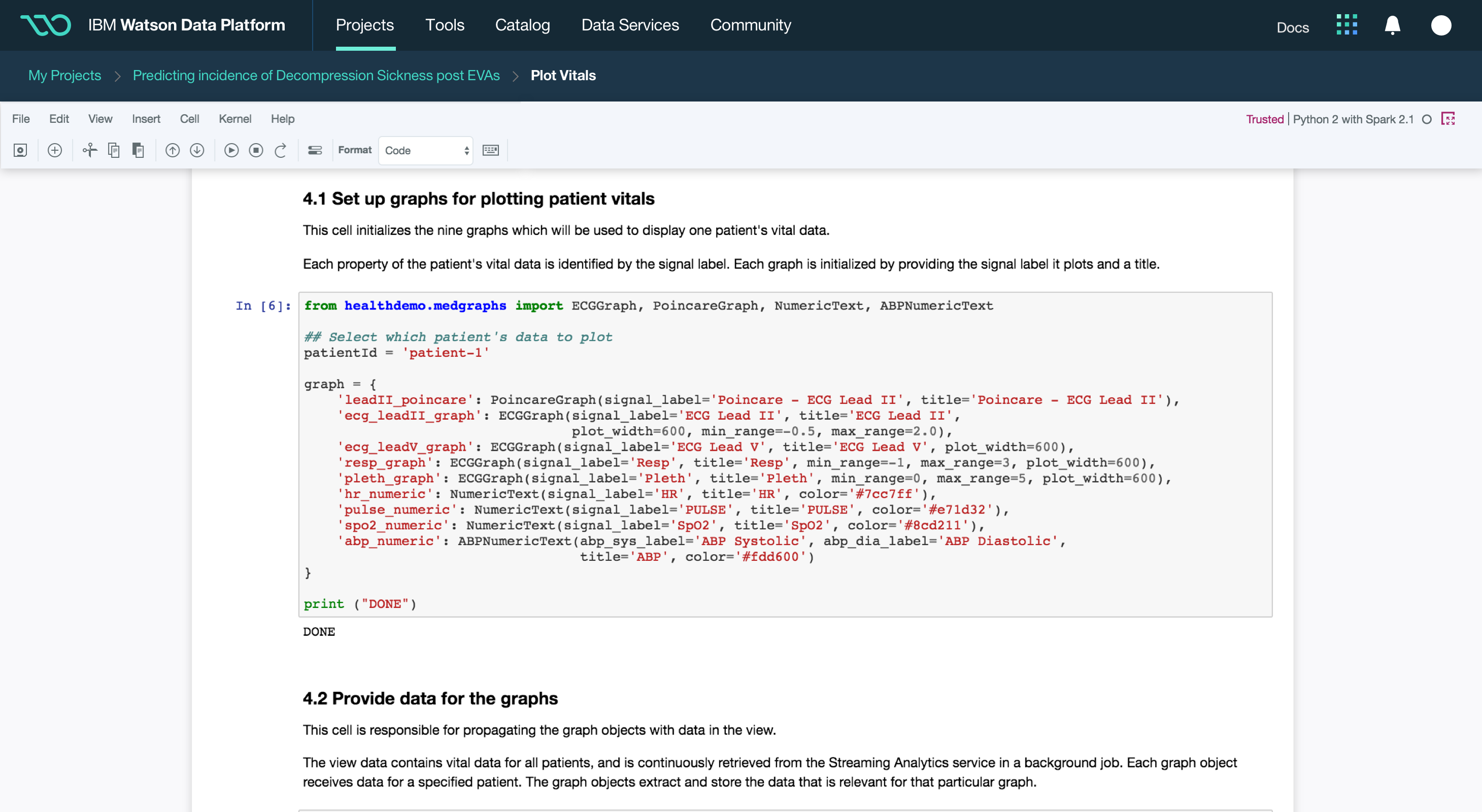
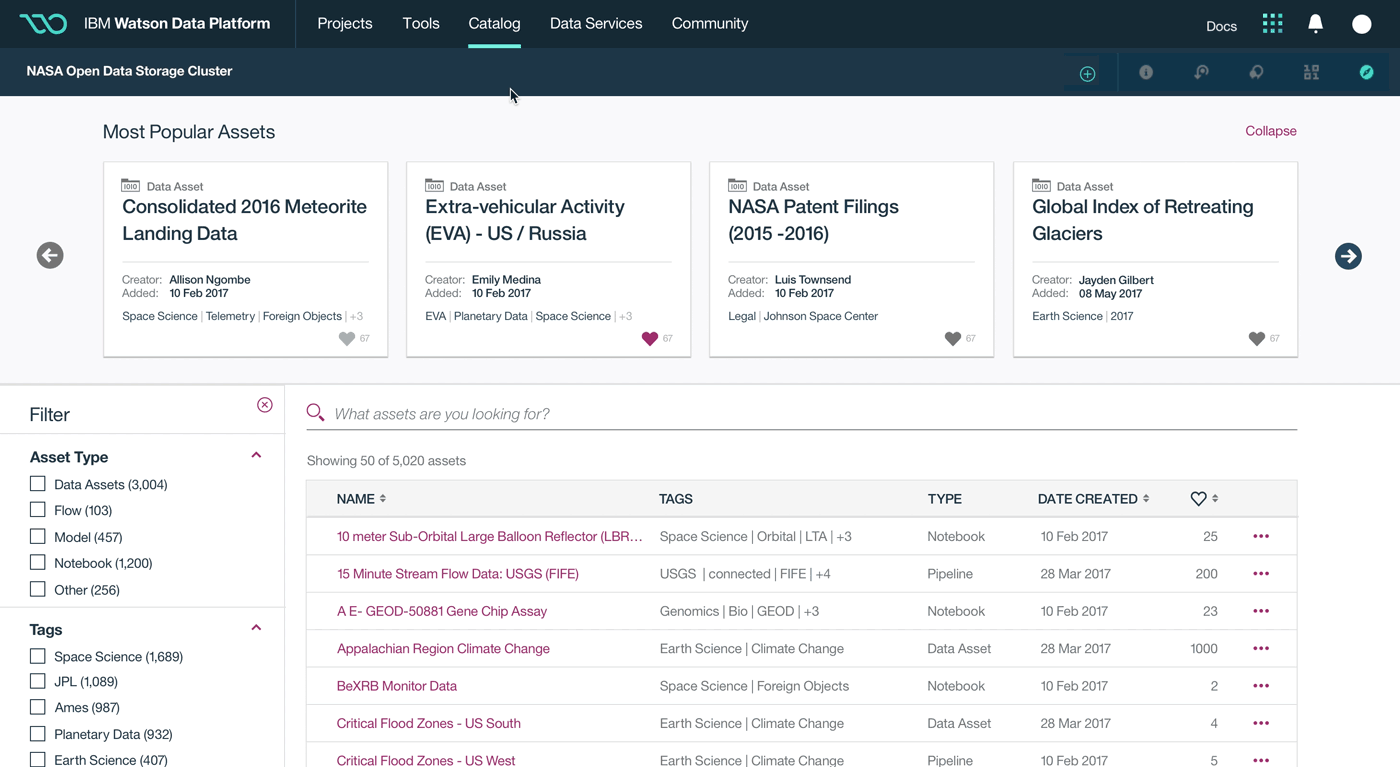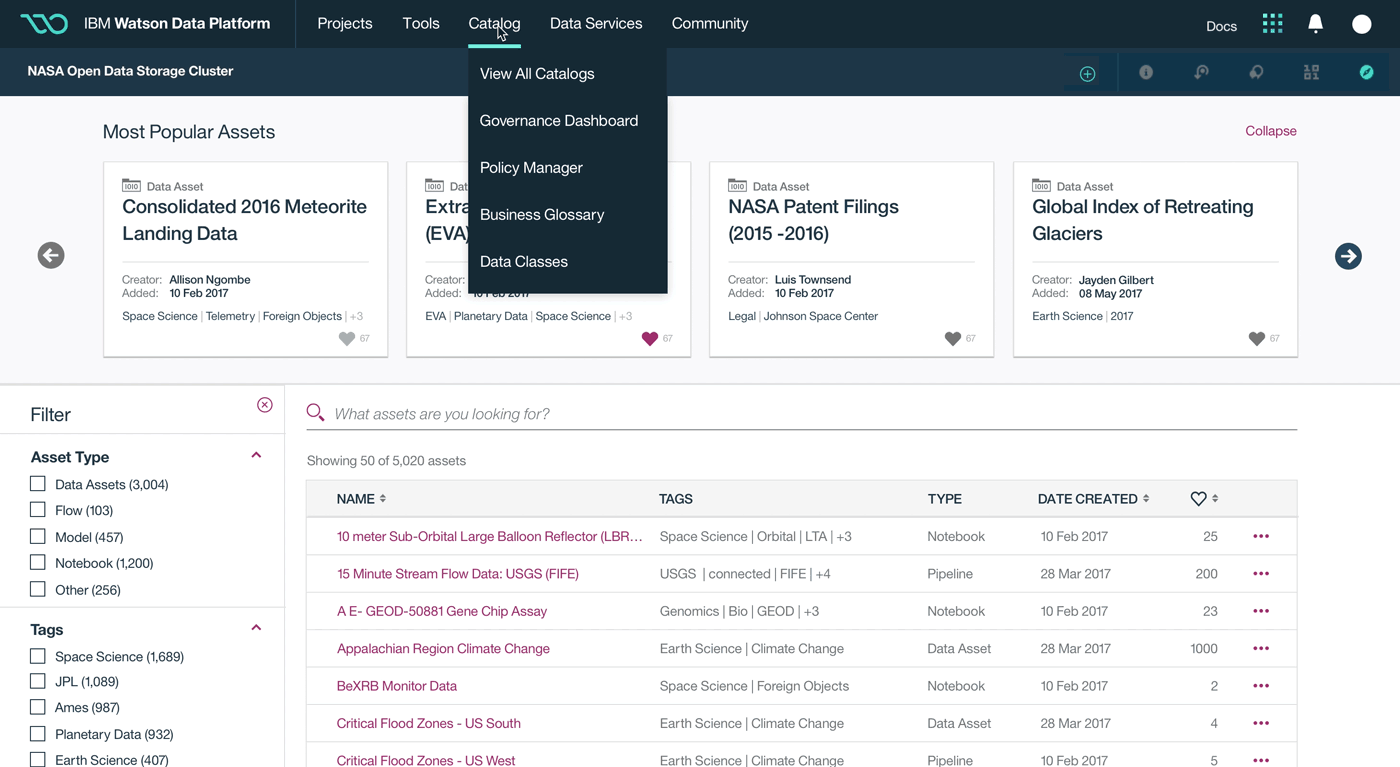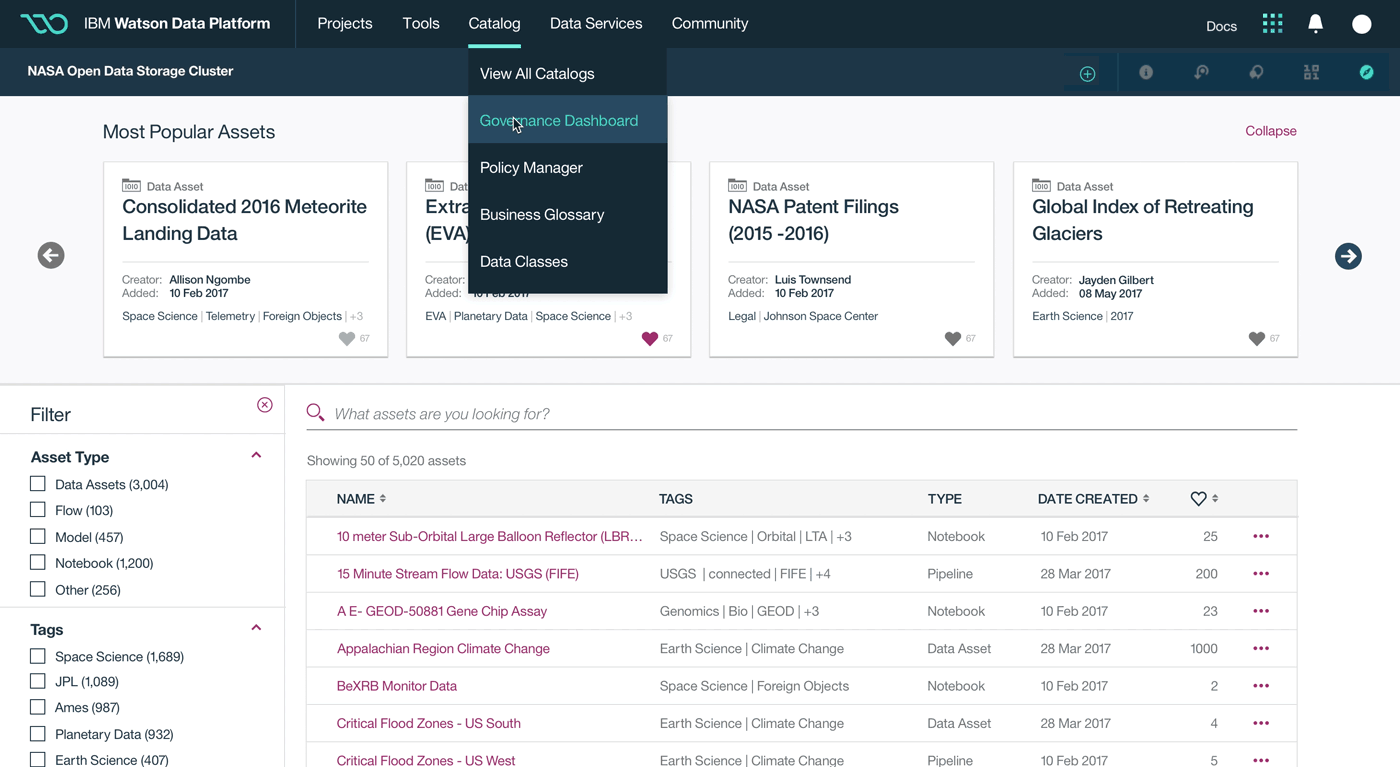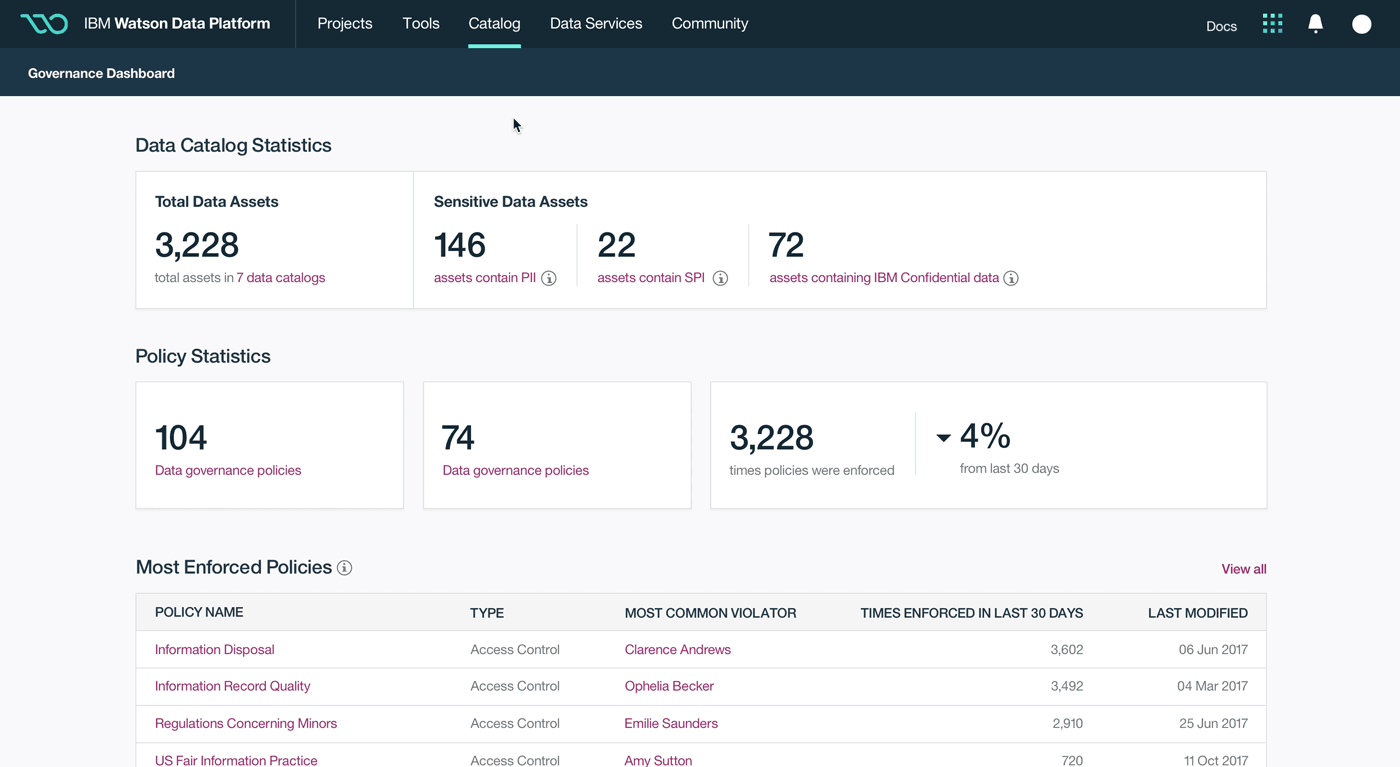
The Watson Data Platform is IBM's first cloud native data cataloging and analytics product designed to facilitate industrial-scale data science, machine learning and predictive analytics for the world's largest companies. The product is now live and you can try it for free today.
Project Overview
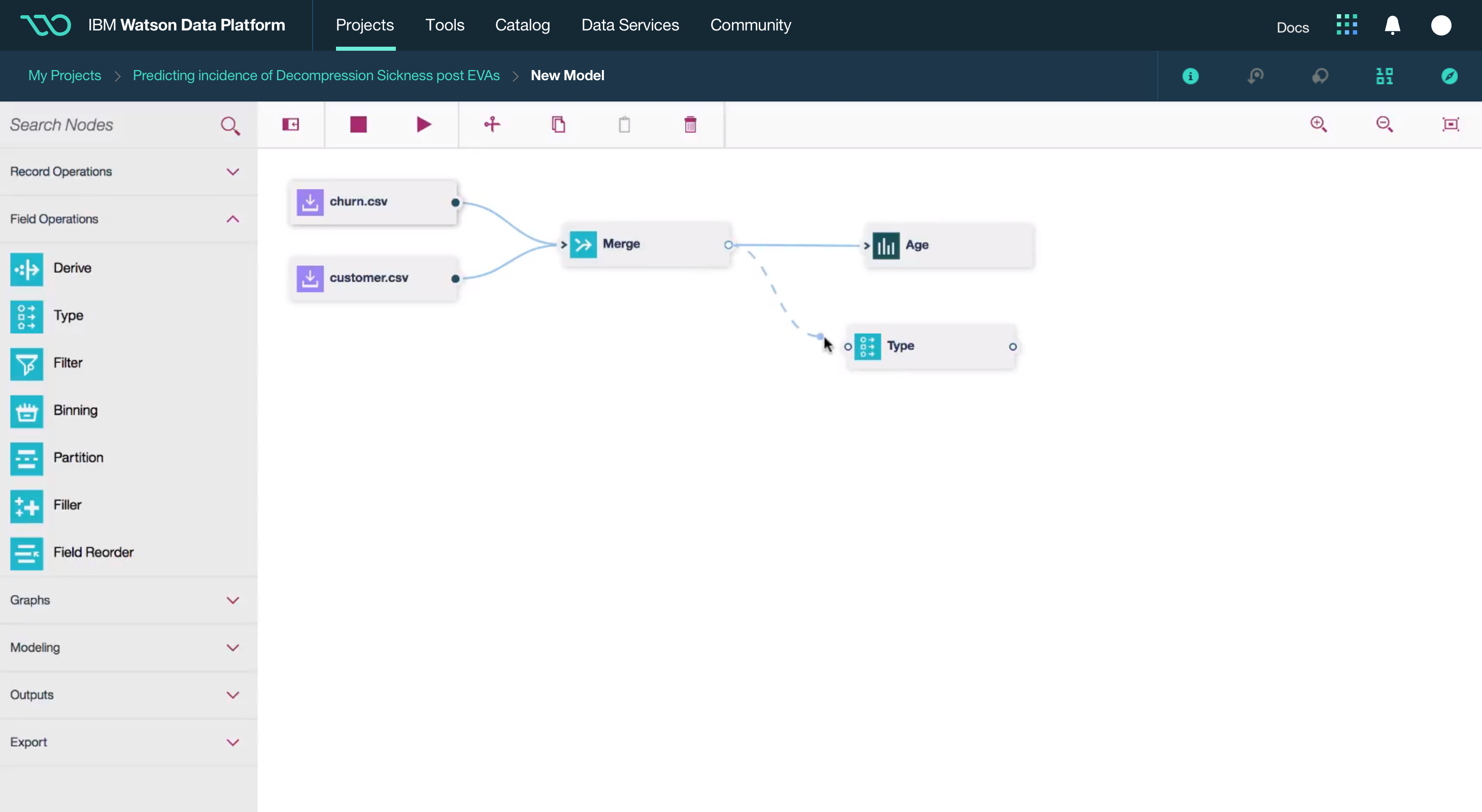
Building off the success and visual language of IBM's Data Science Experience, Watson Data Platform is the result of a years-long effort to redesign legacy big data tools and combine them in a single cloud platform.
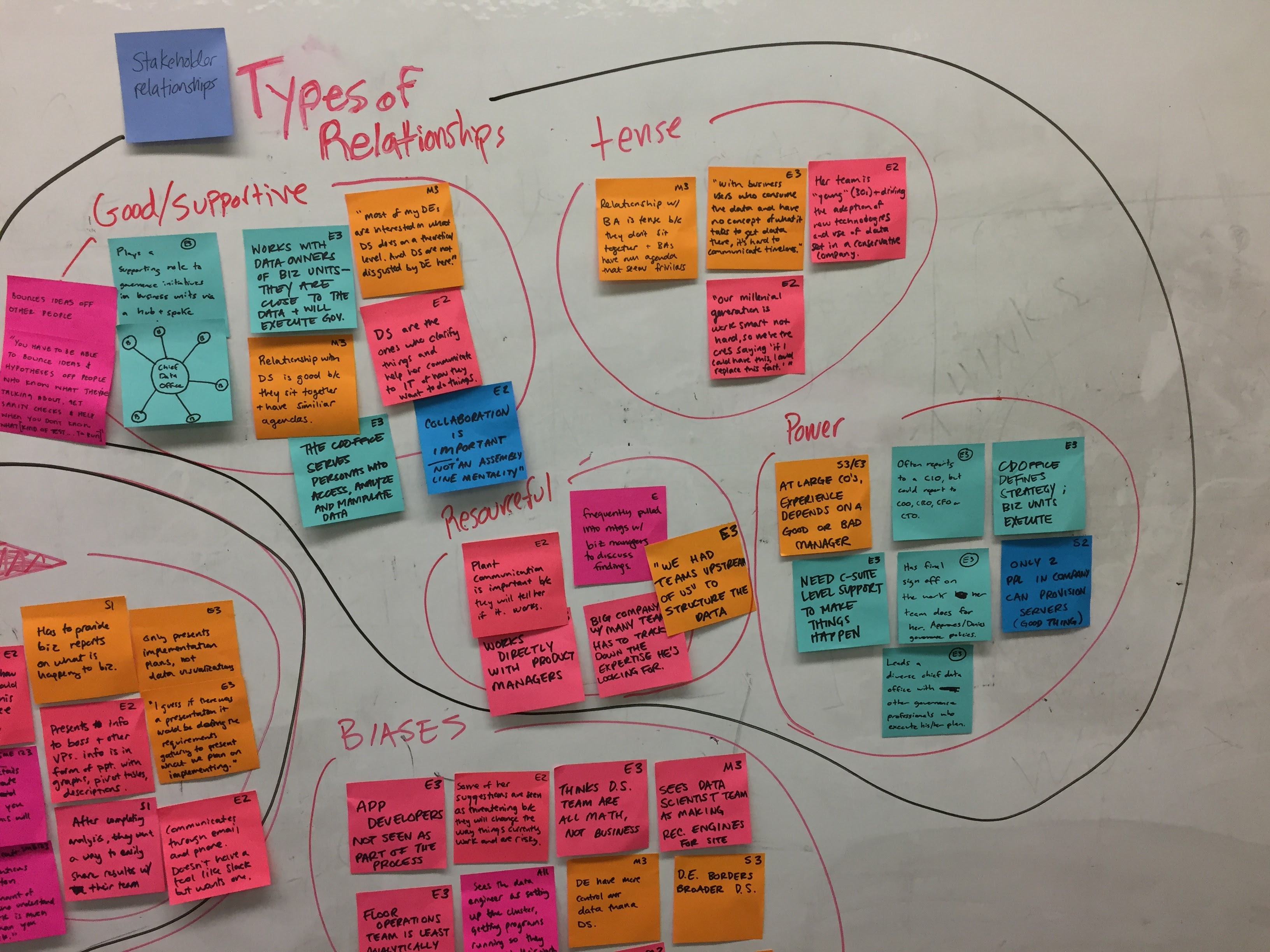
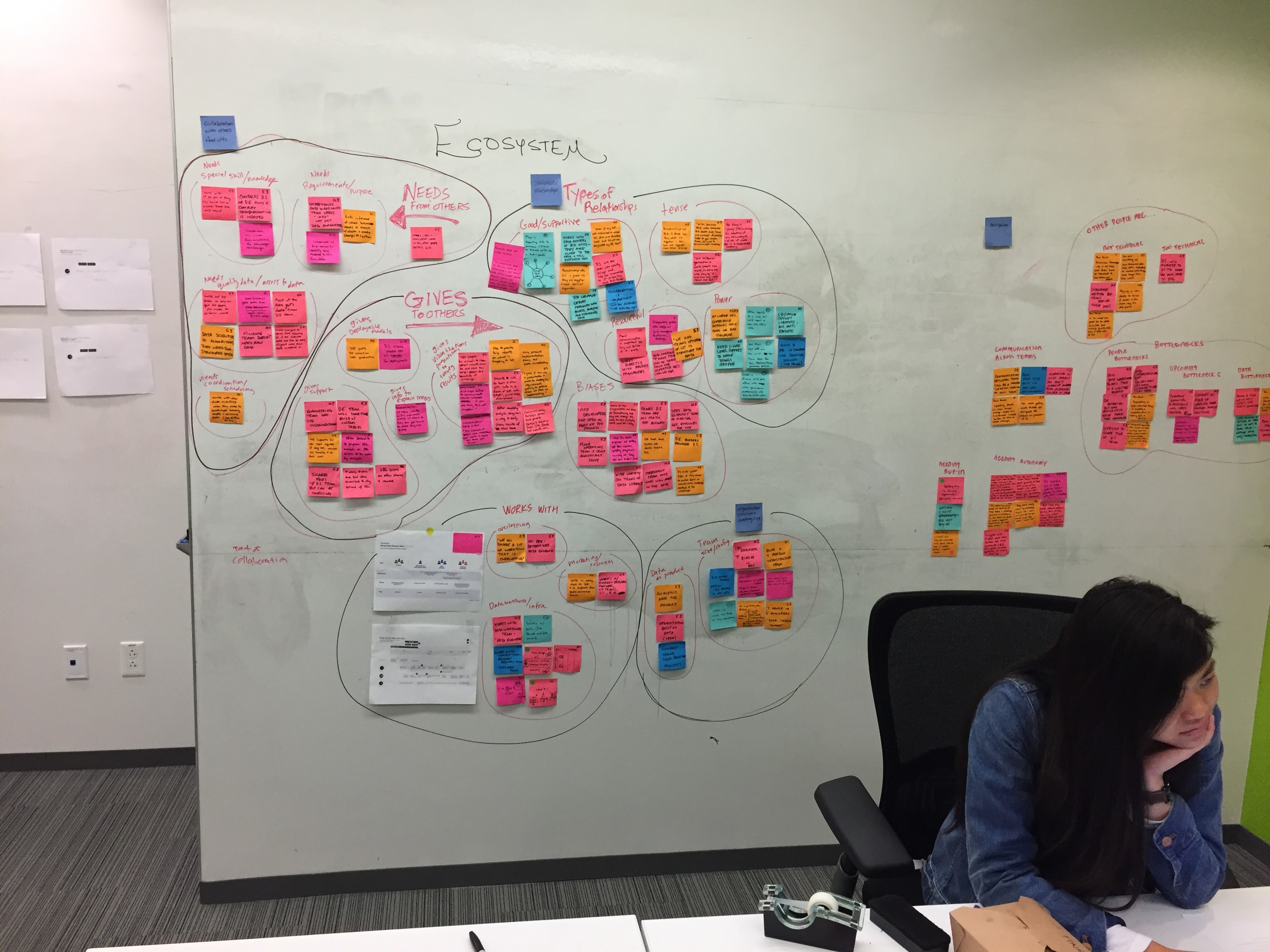
Using human-centered methodologies, our team of 60 designers, researchers and front-end developers worked with a legion of product managers and software engineers all around the world to focus on one goal: help data analytics teams work better together.
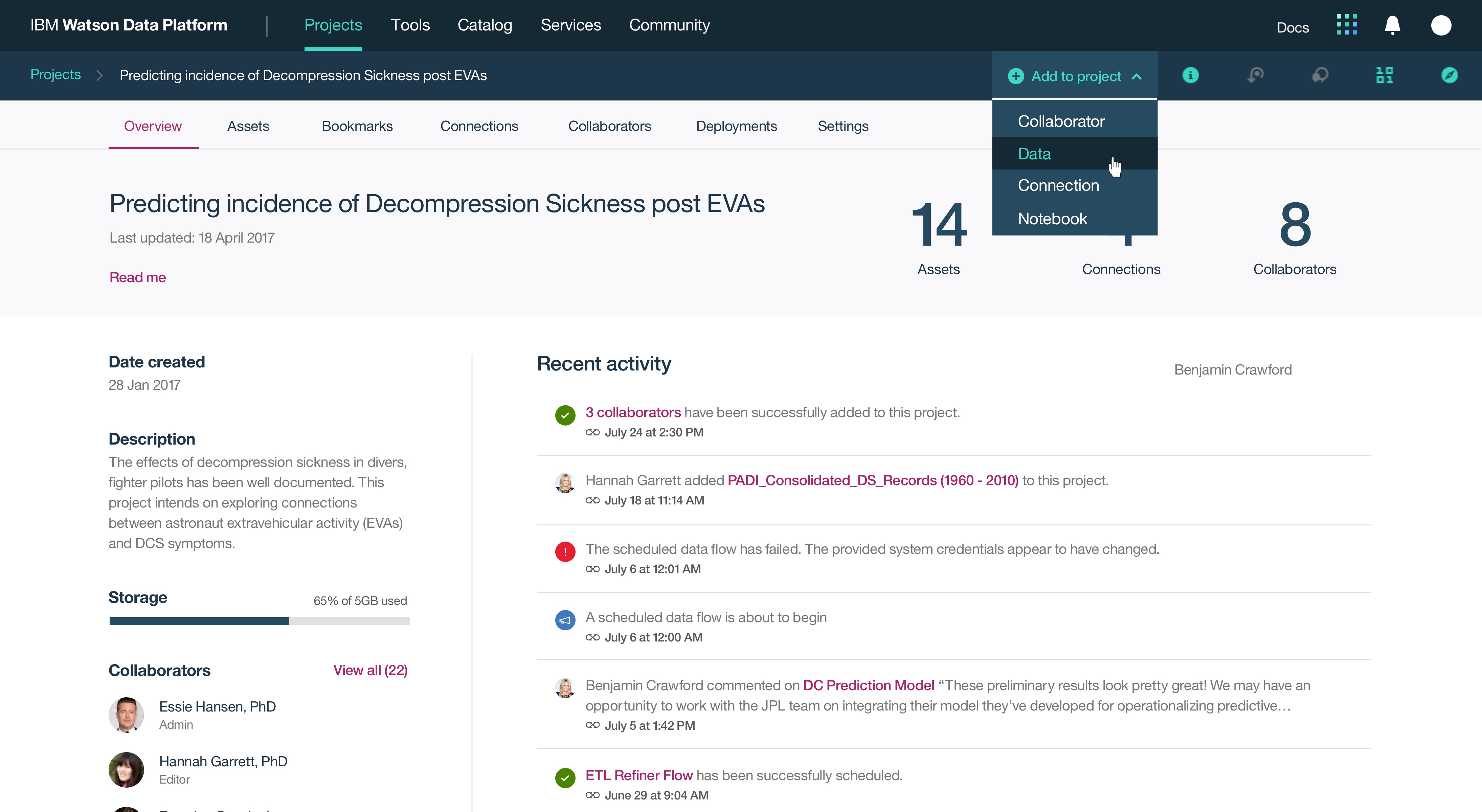
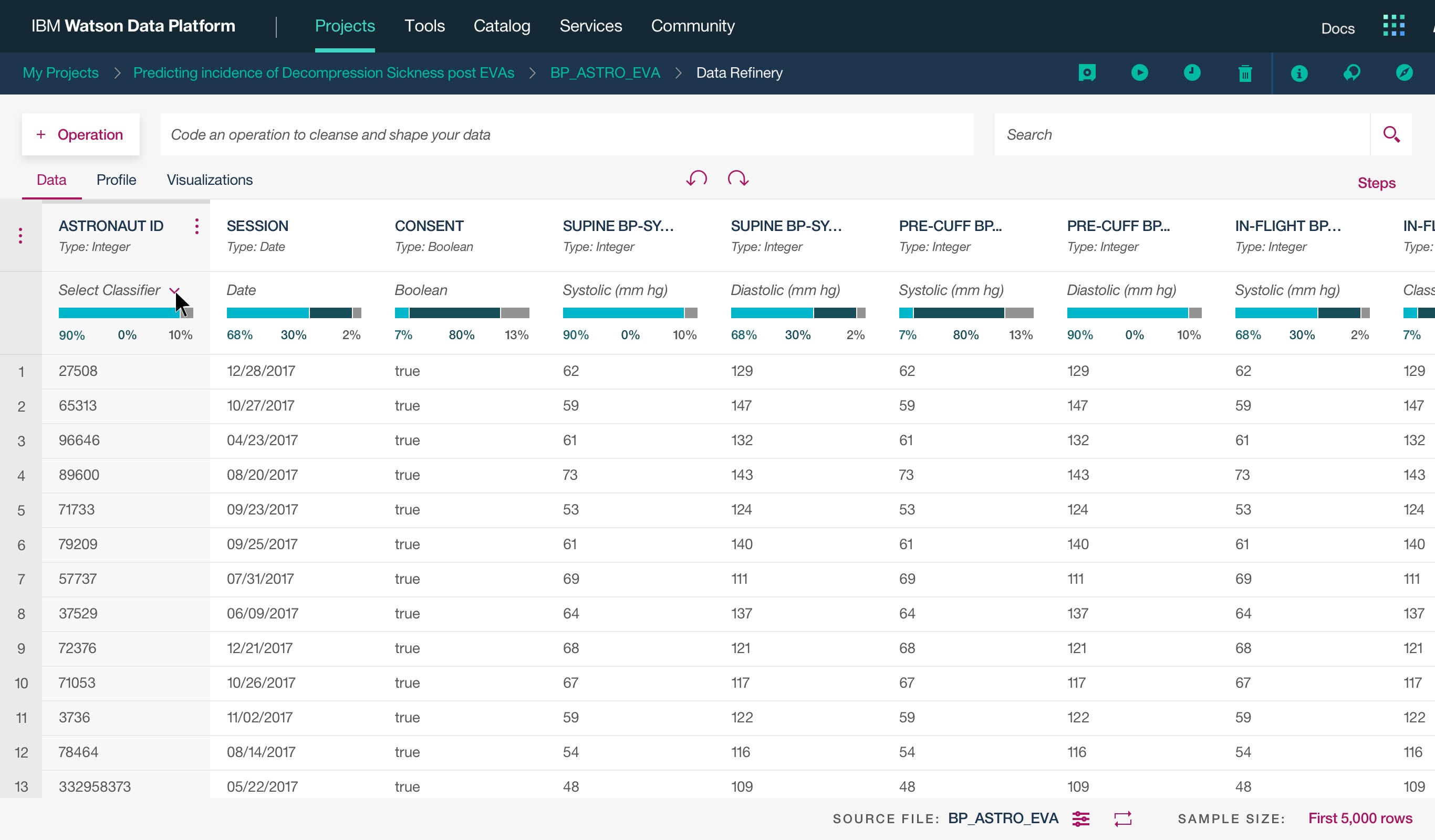
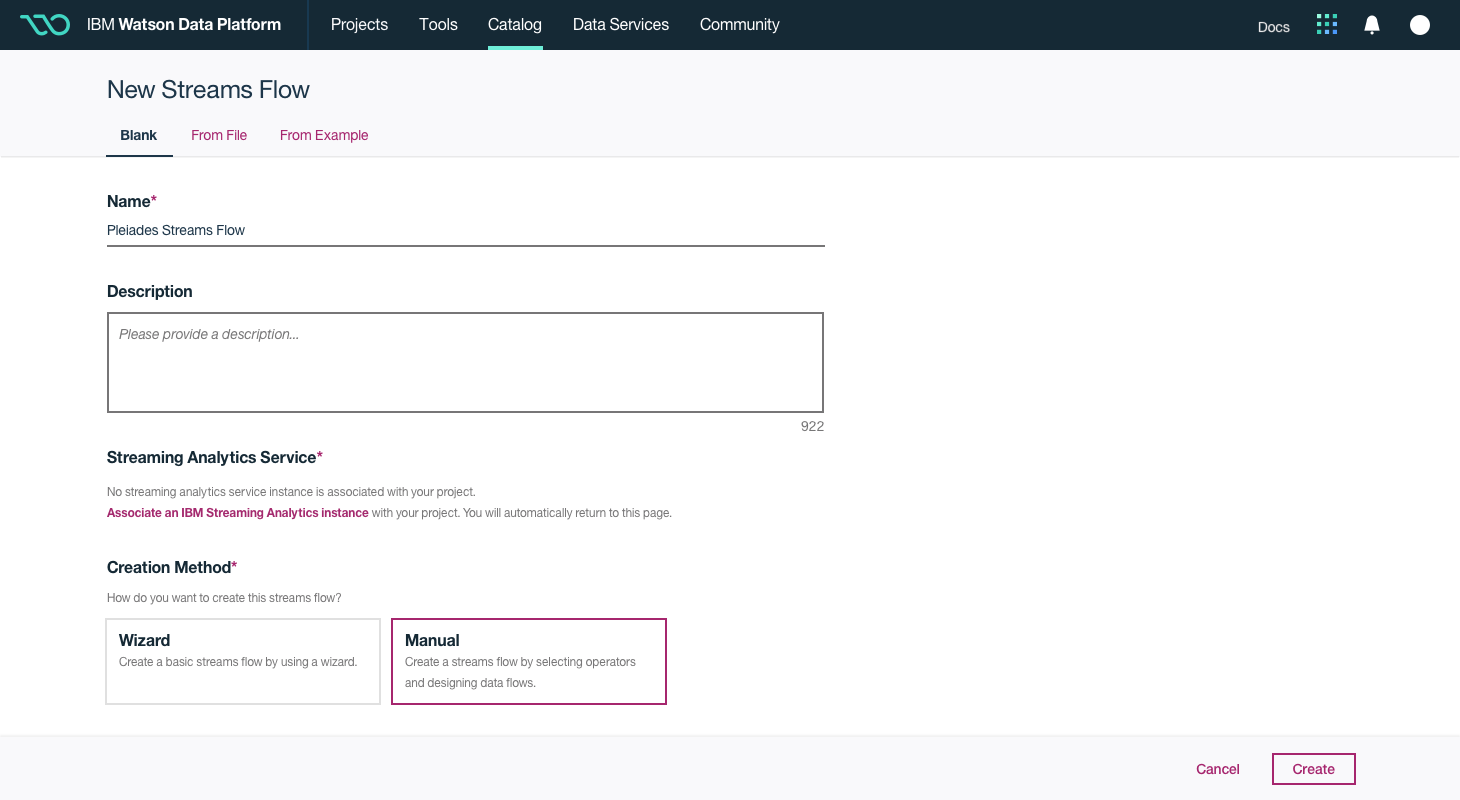
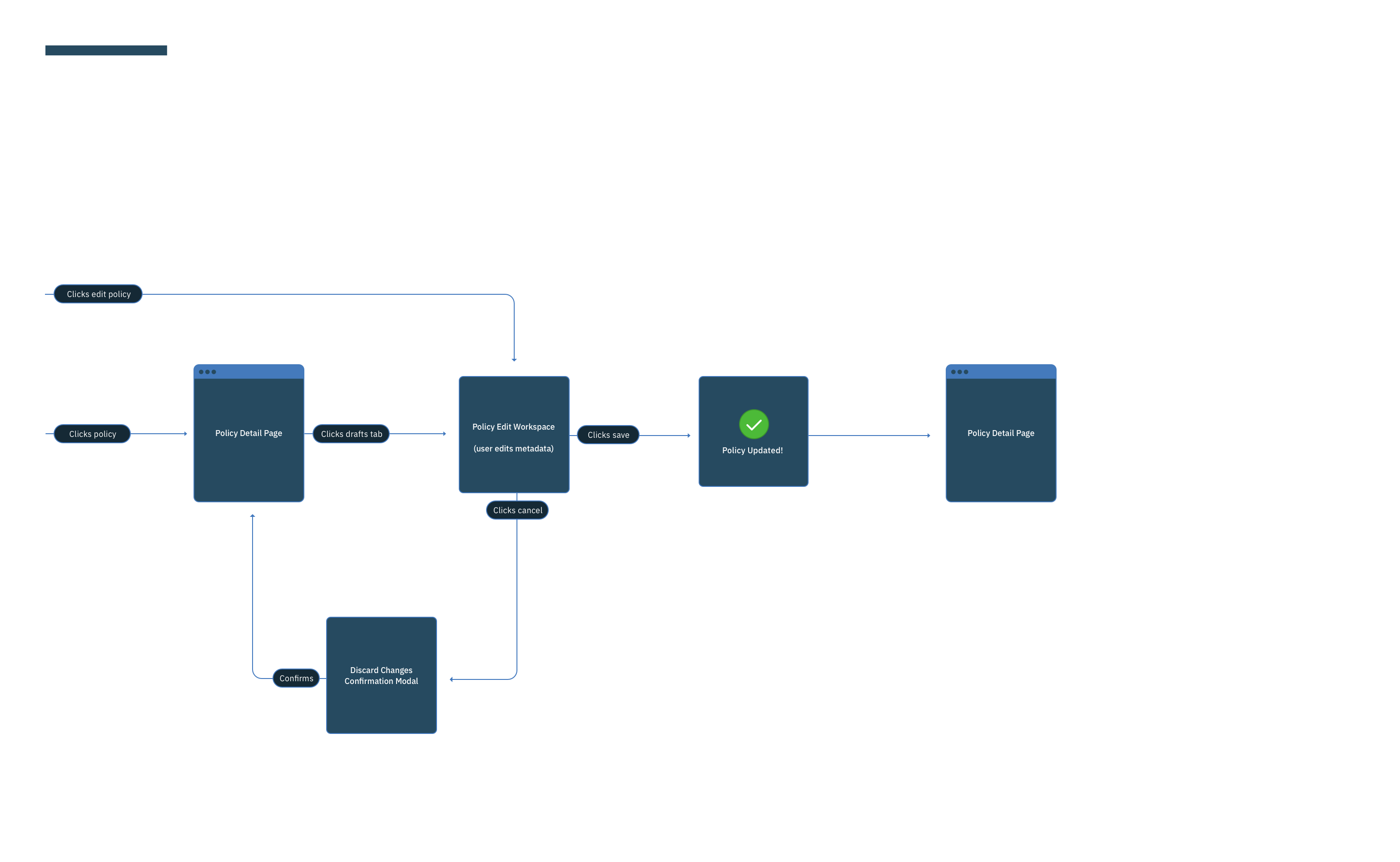
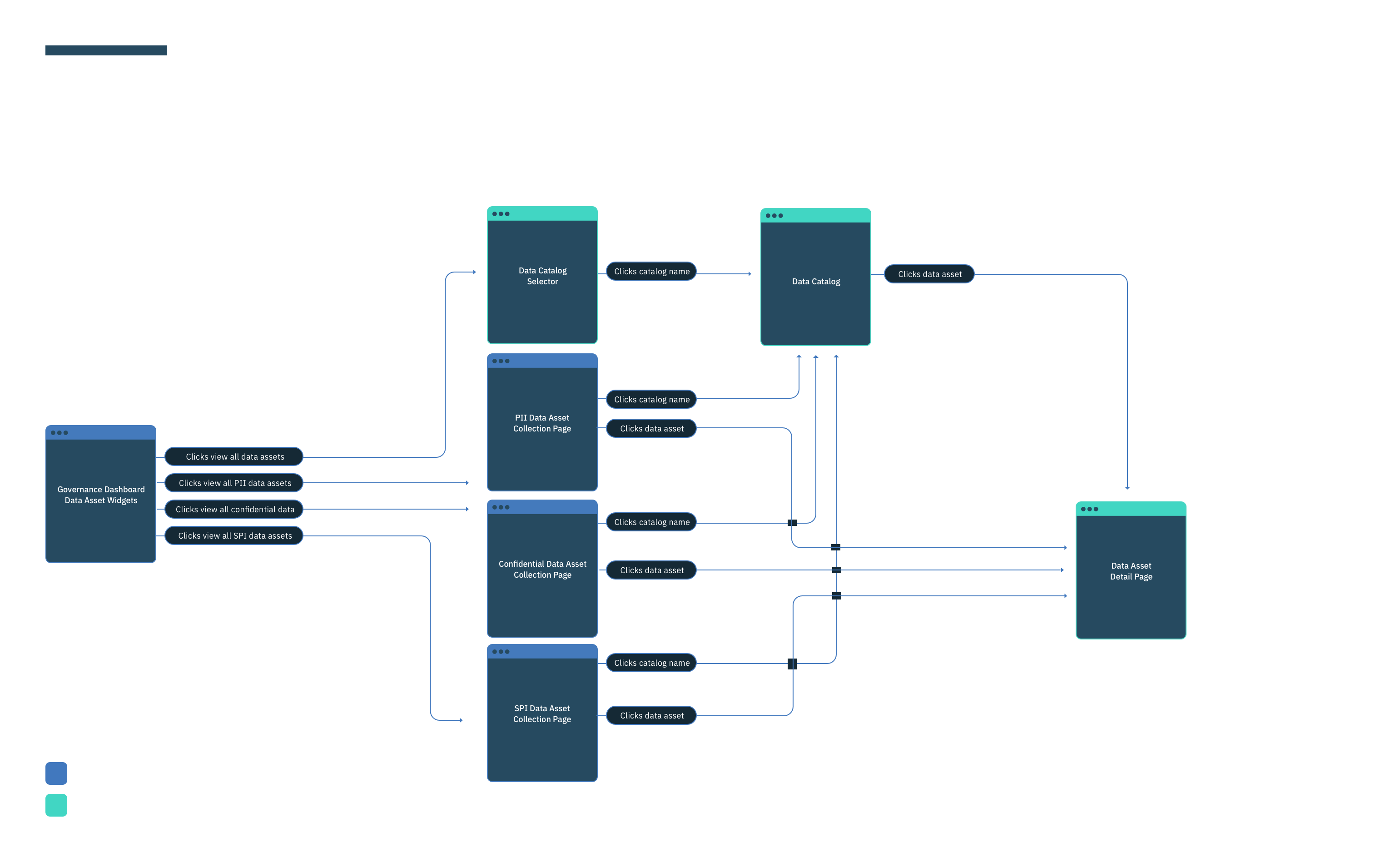
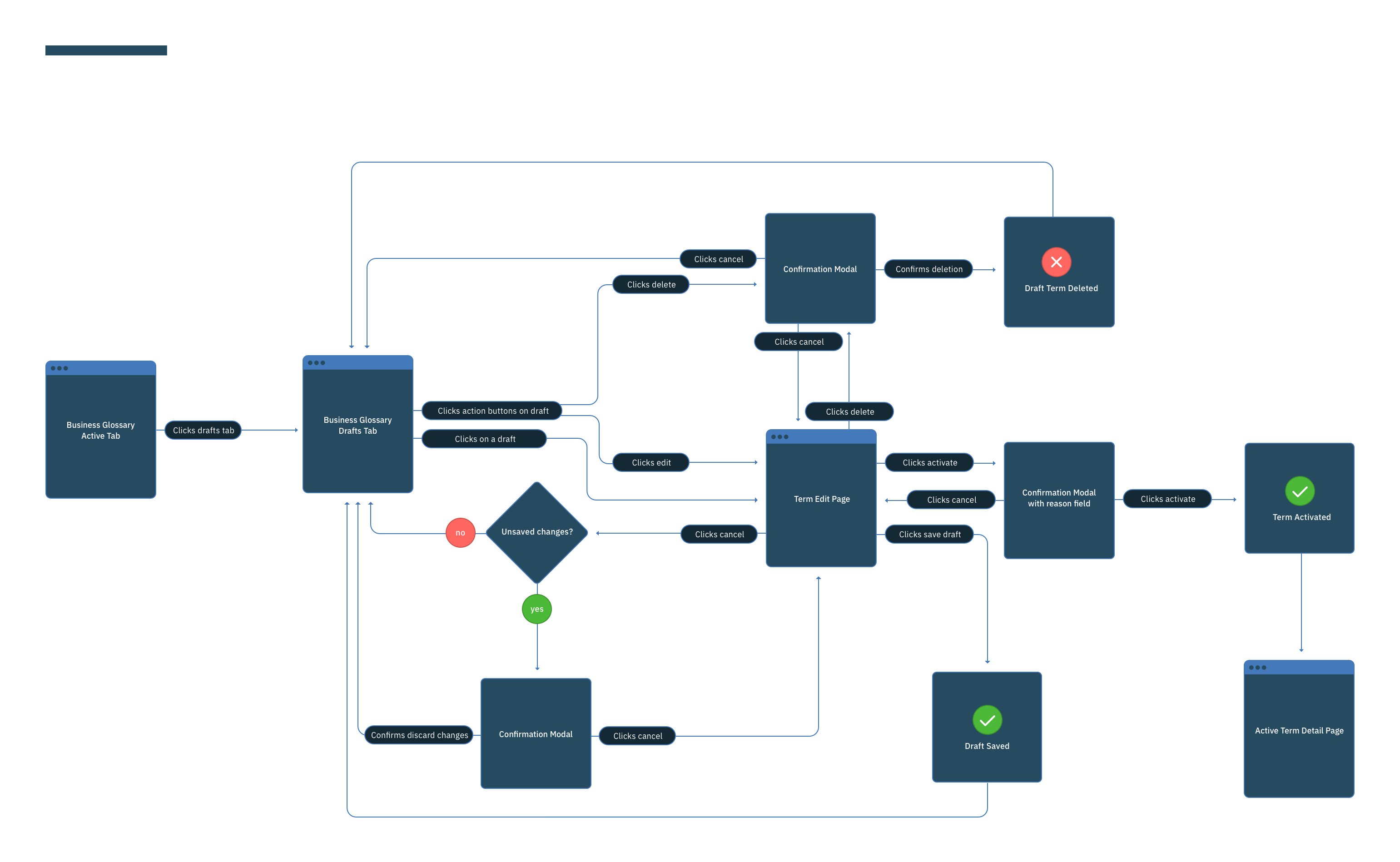
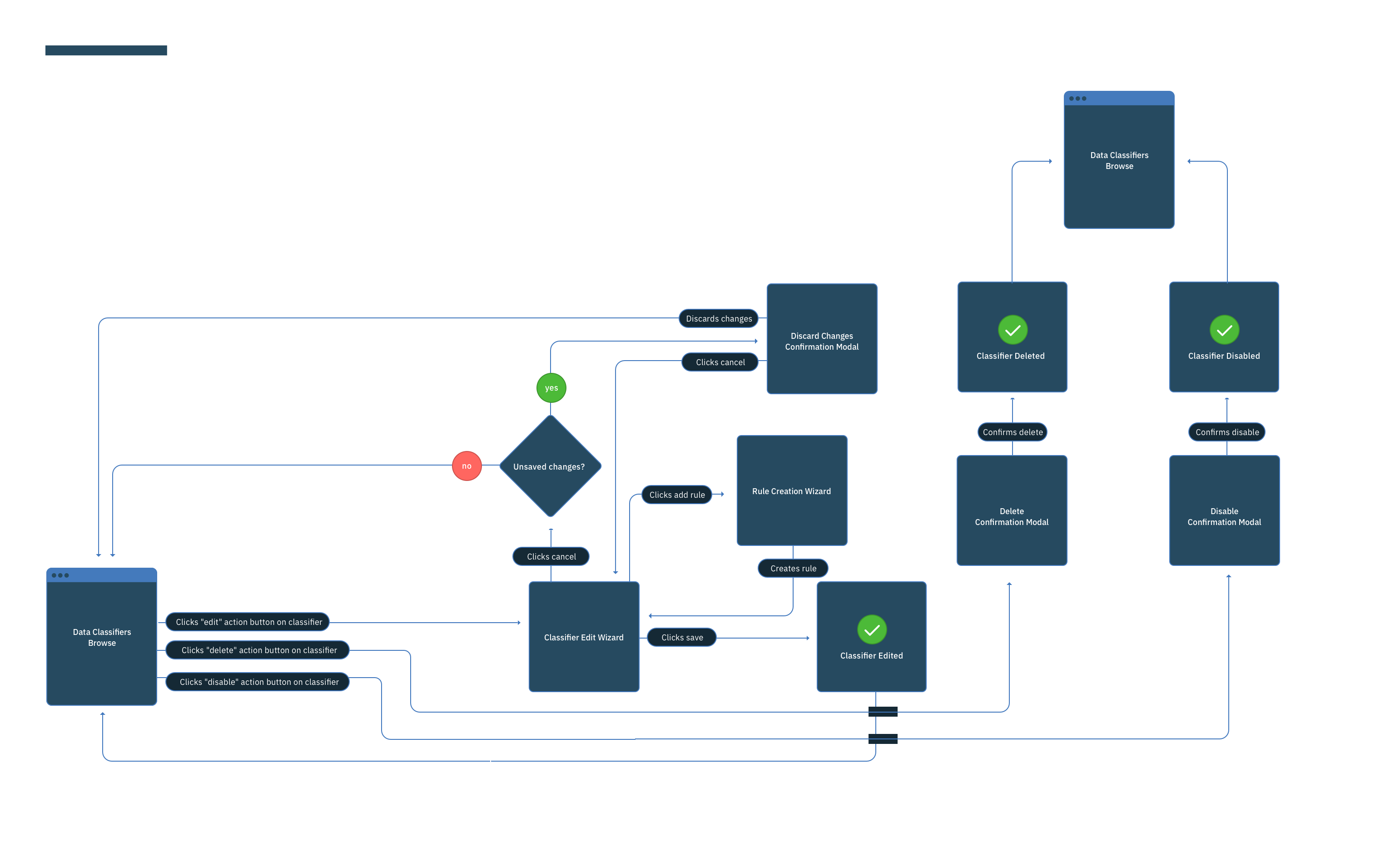
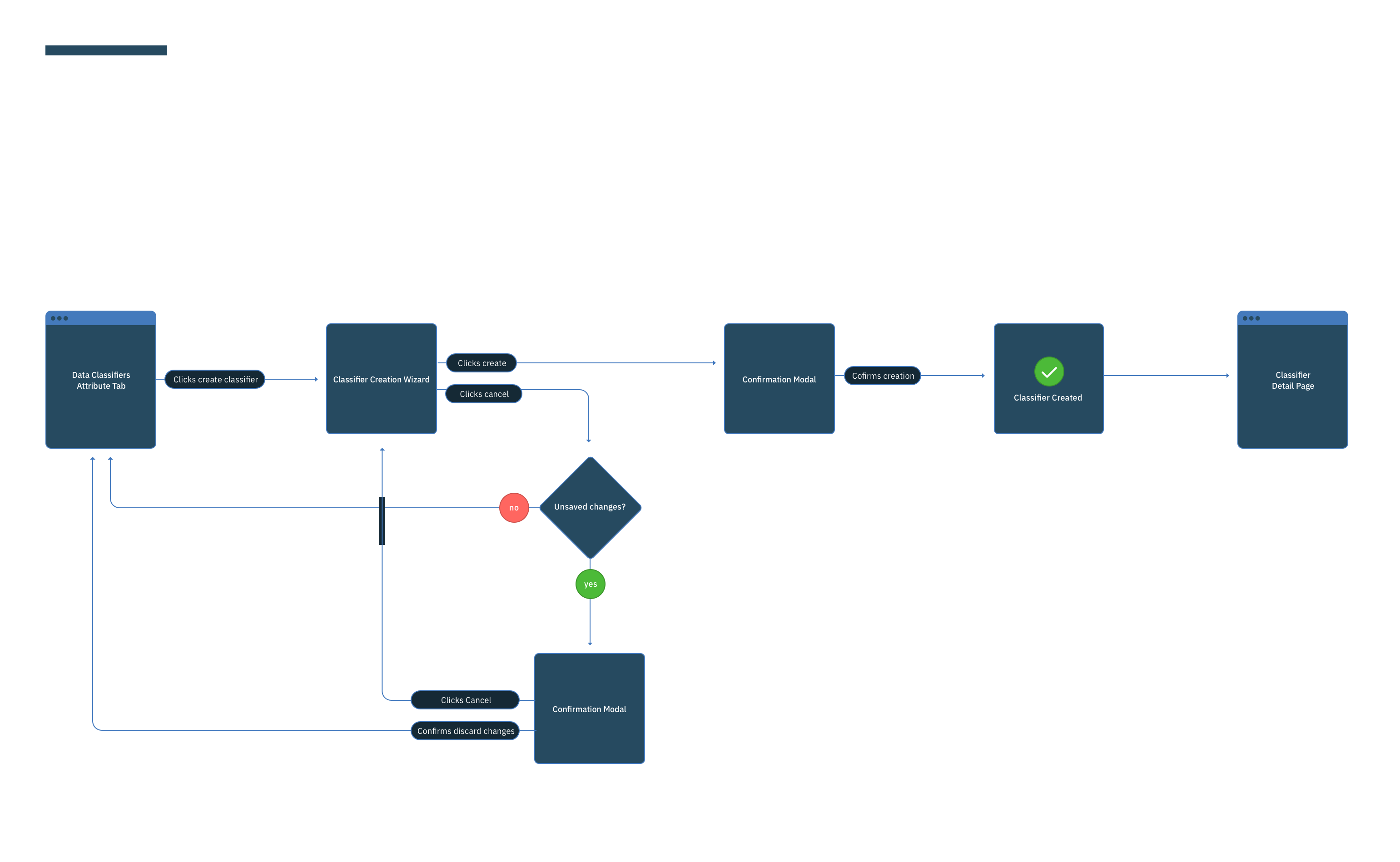
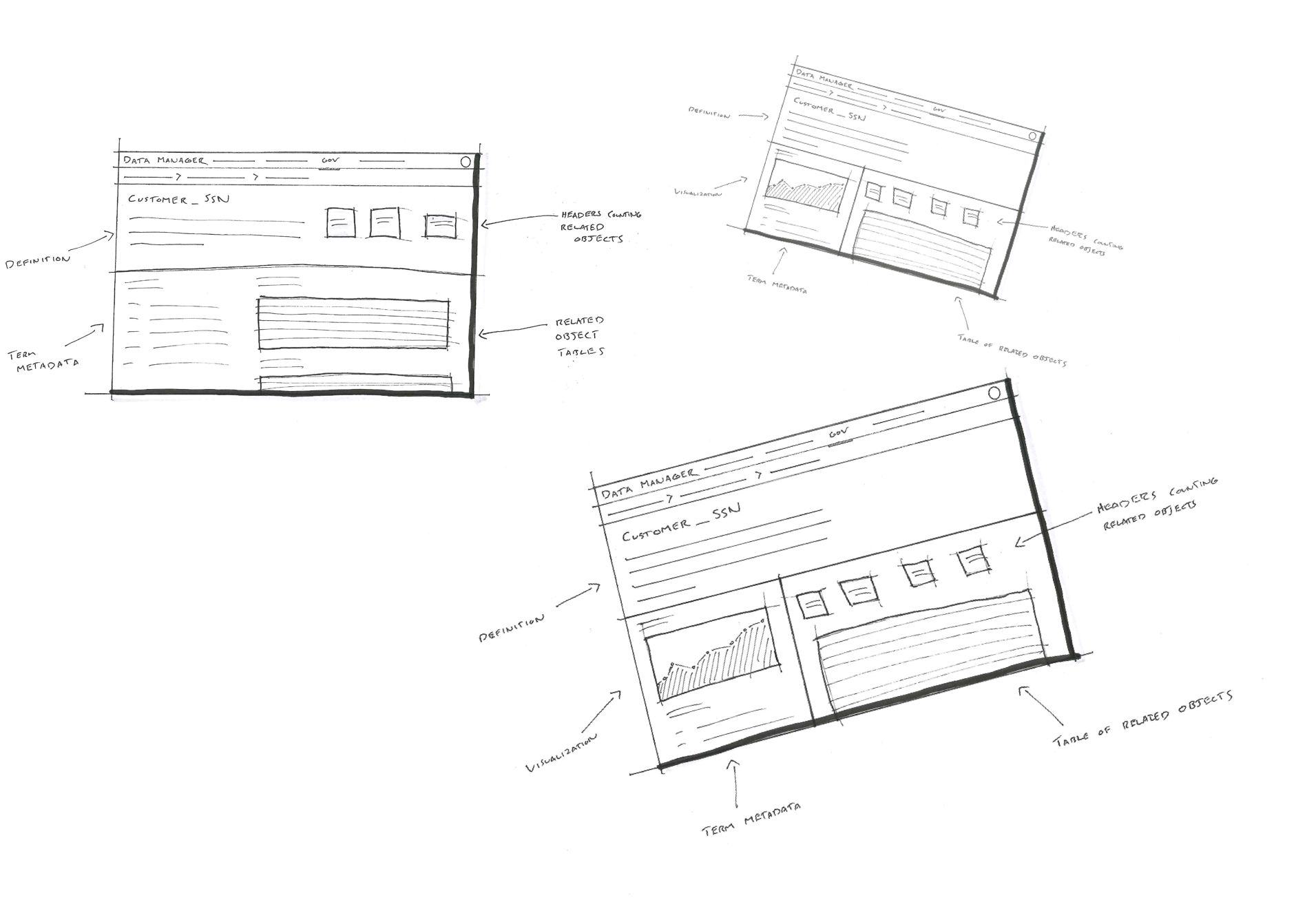
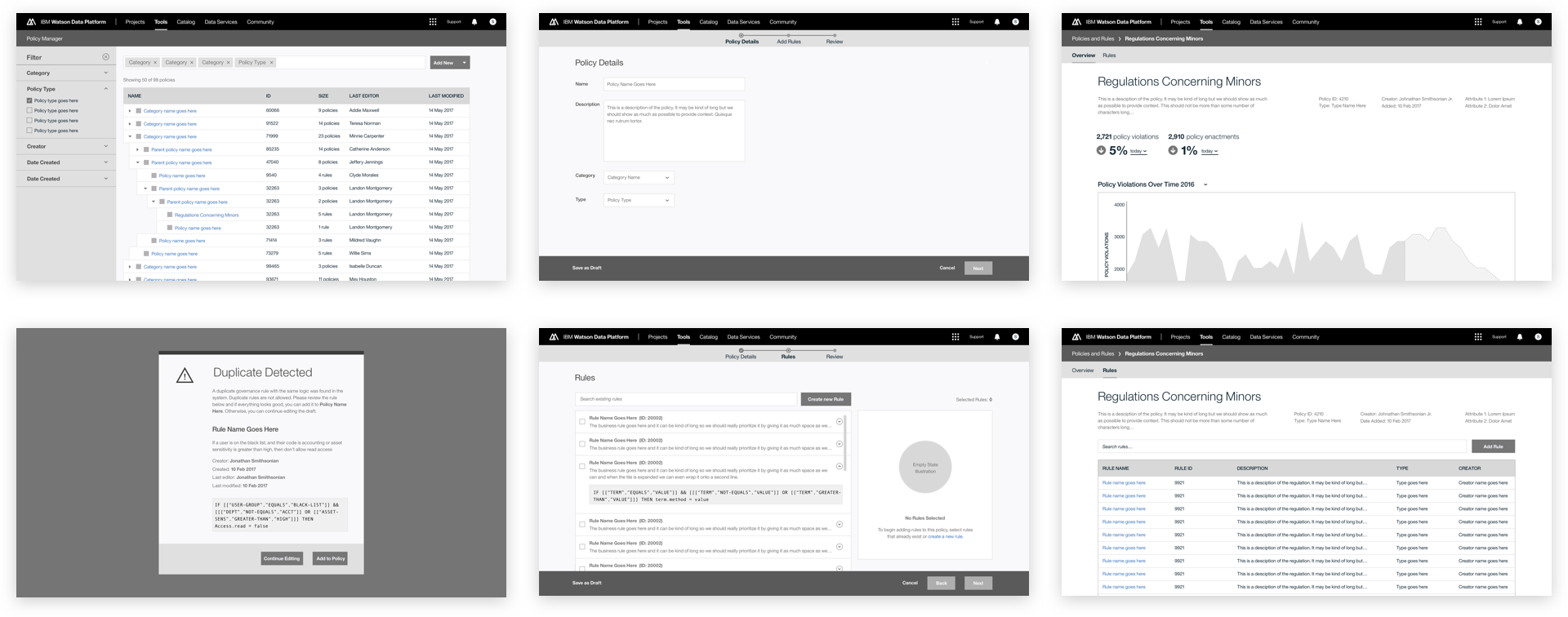
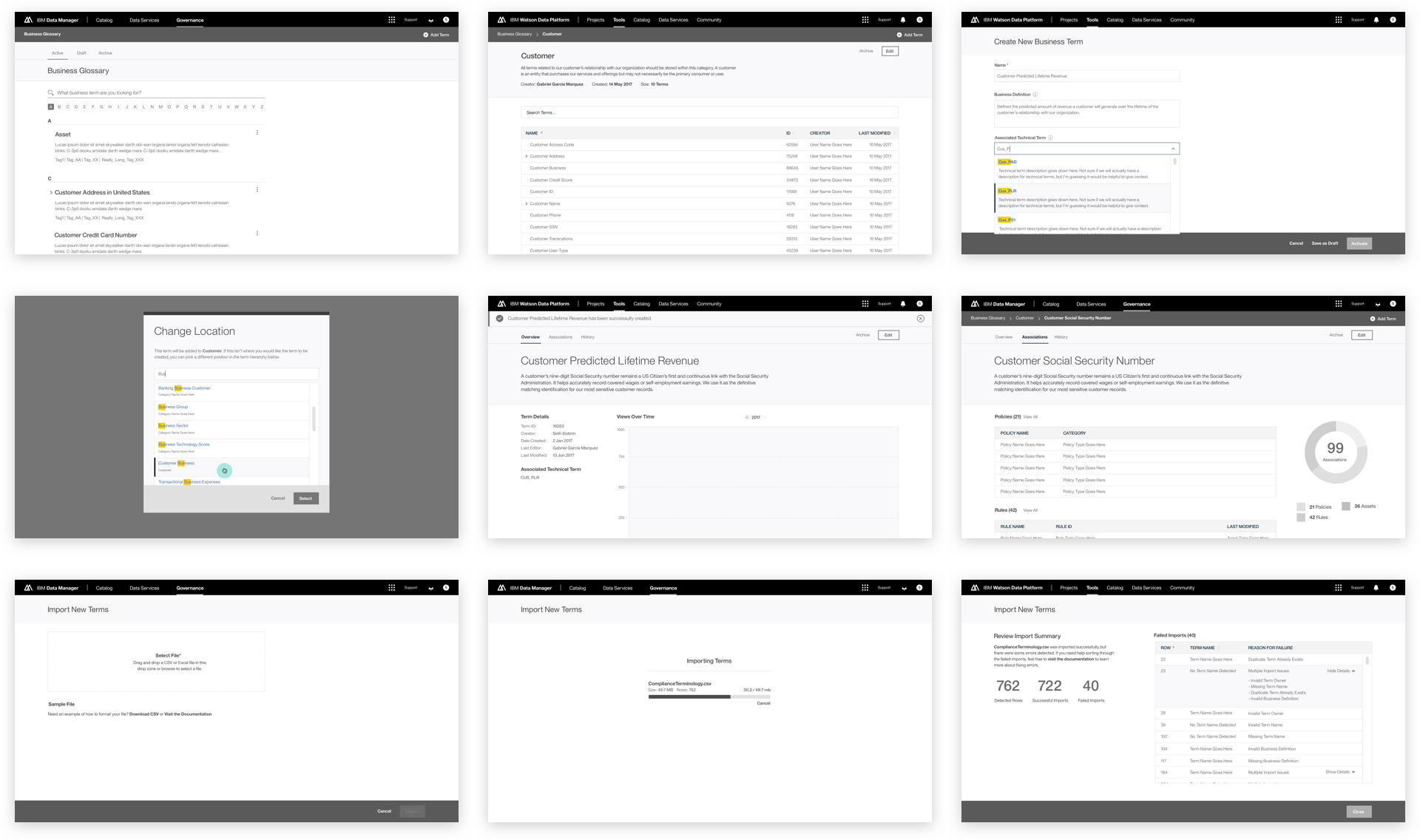
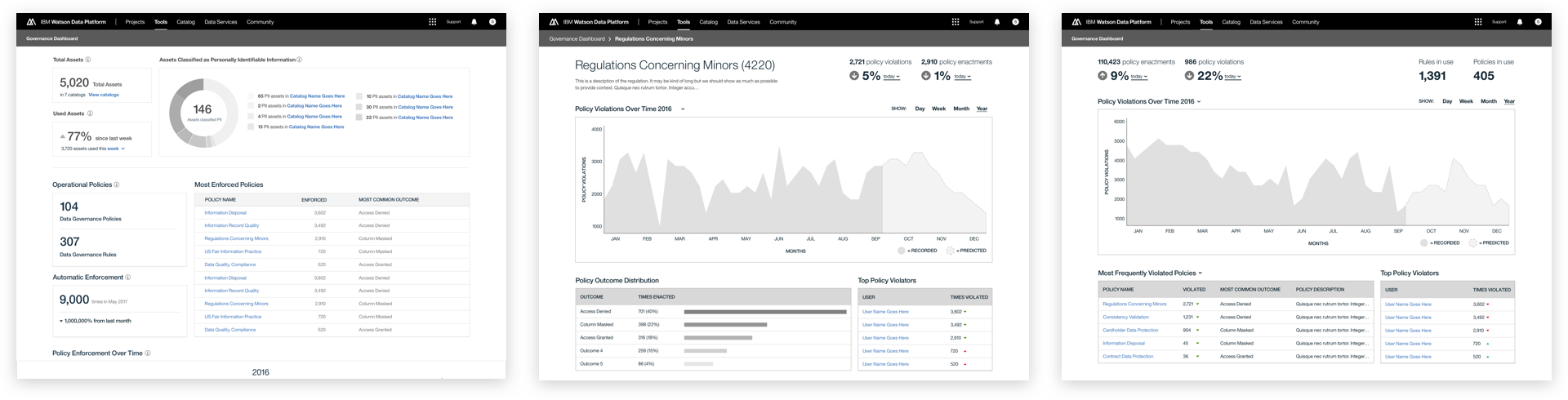
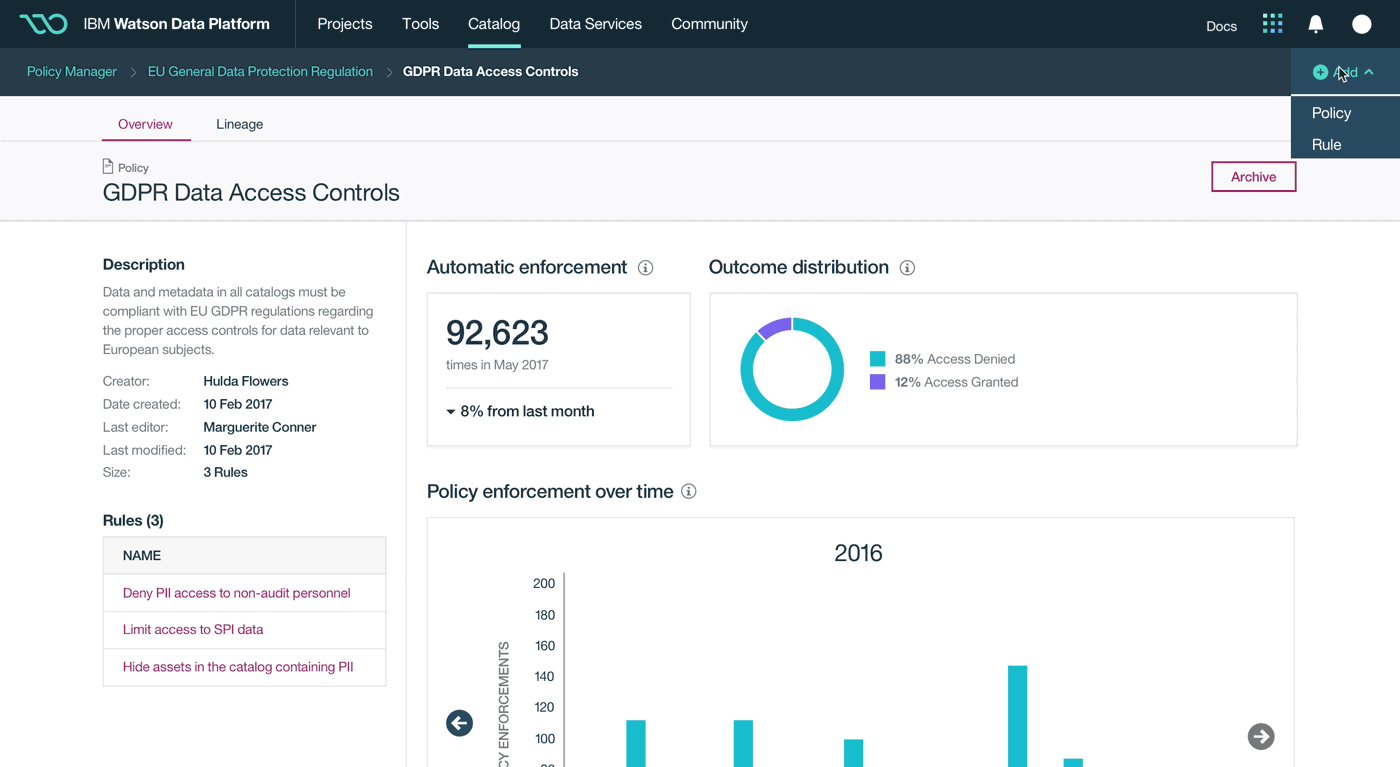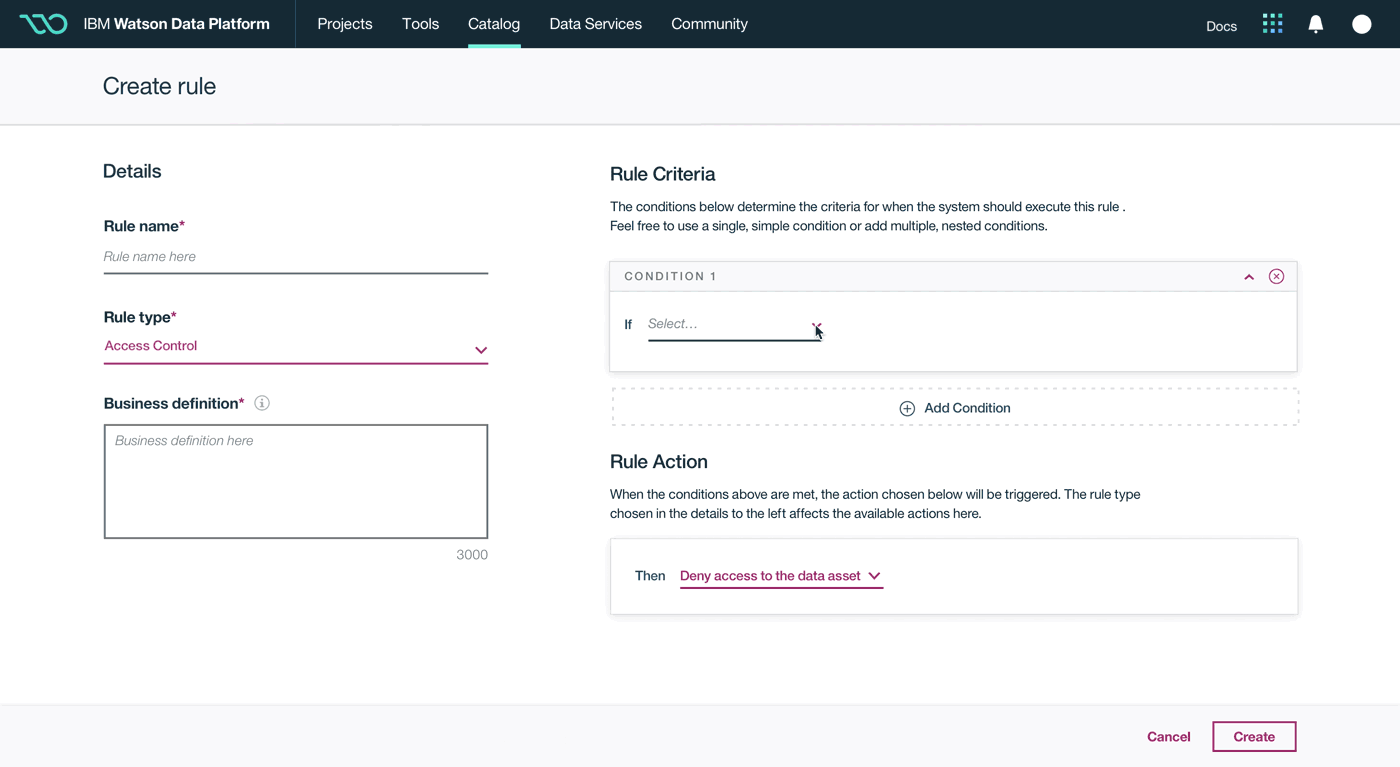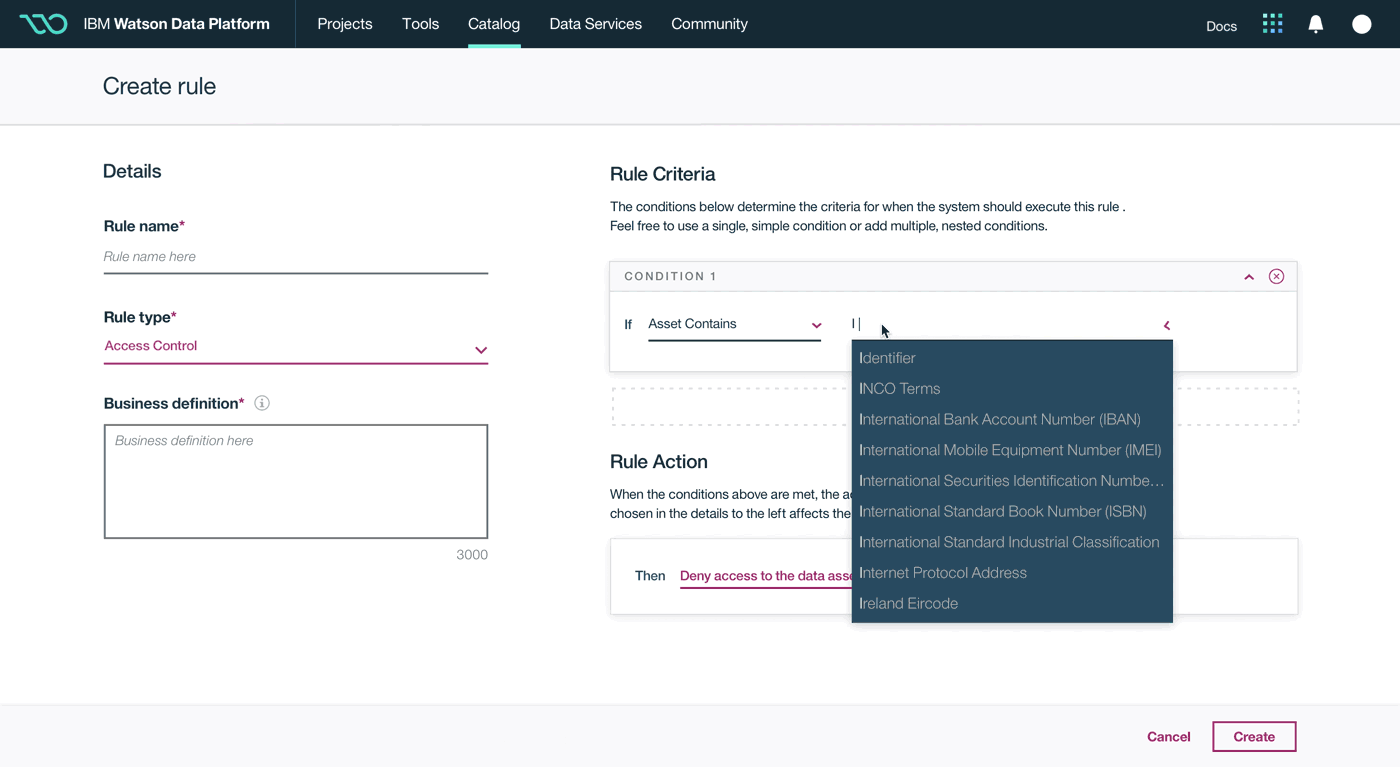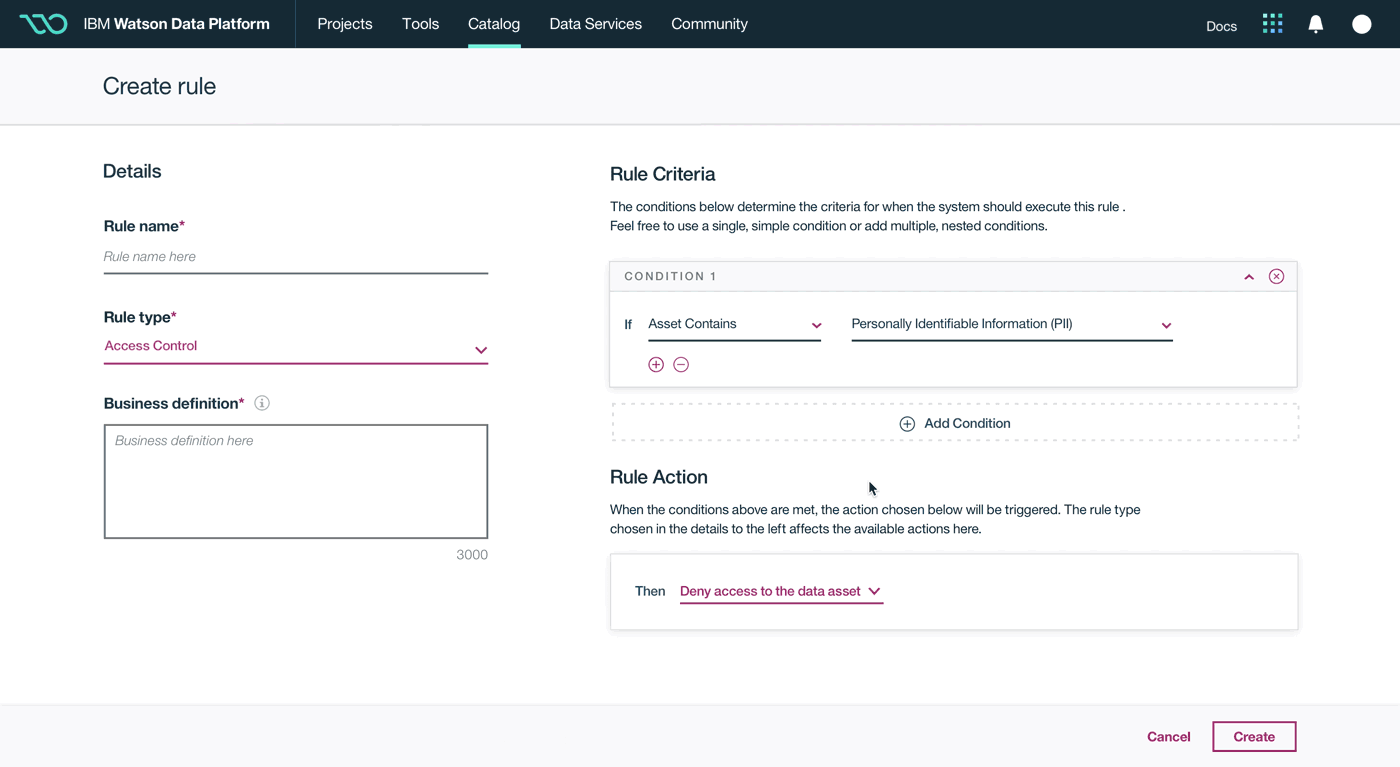
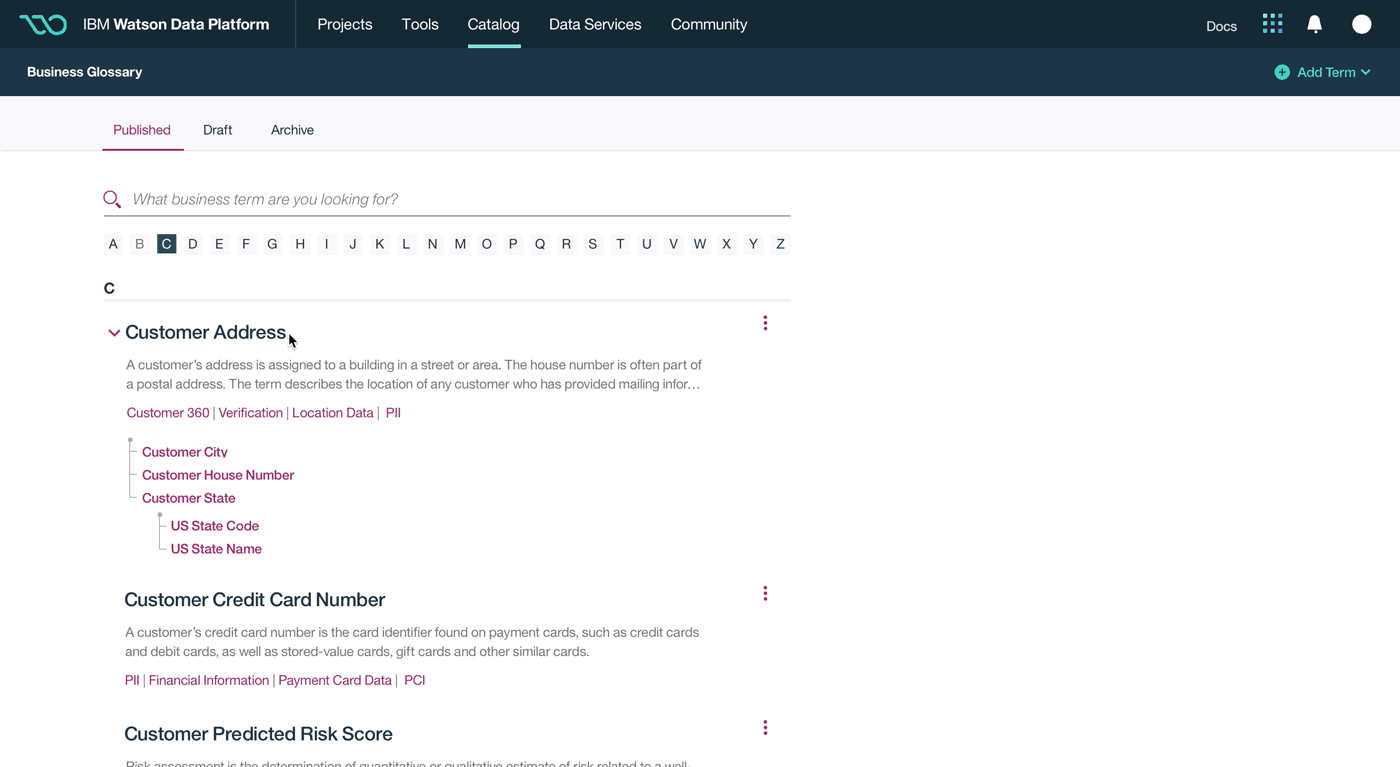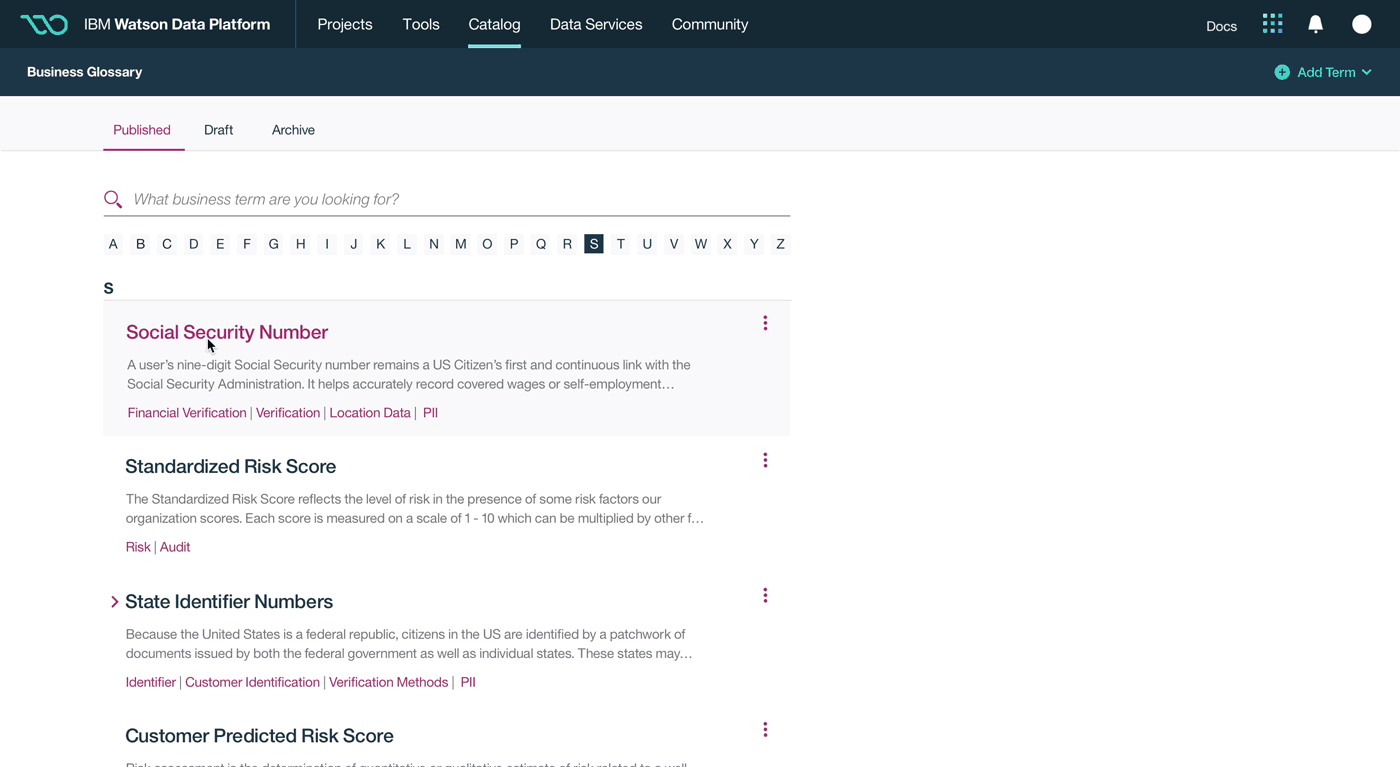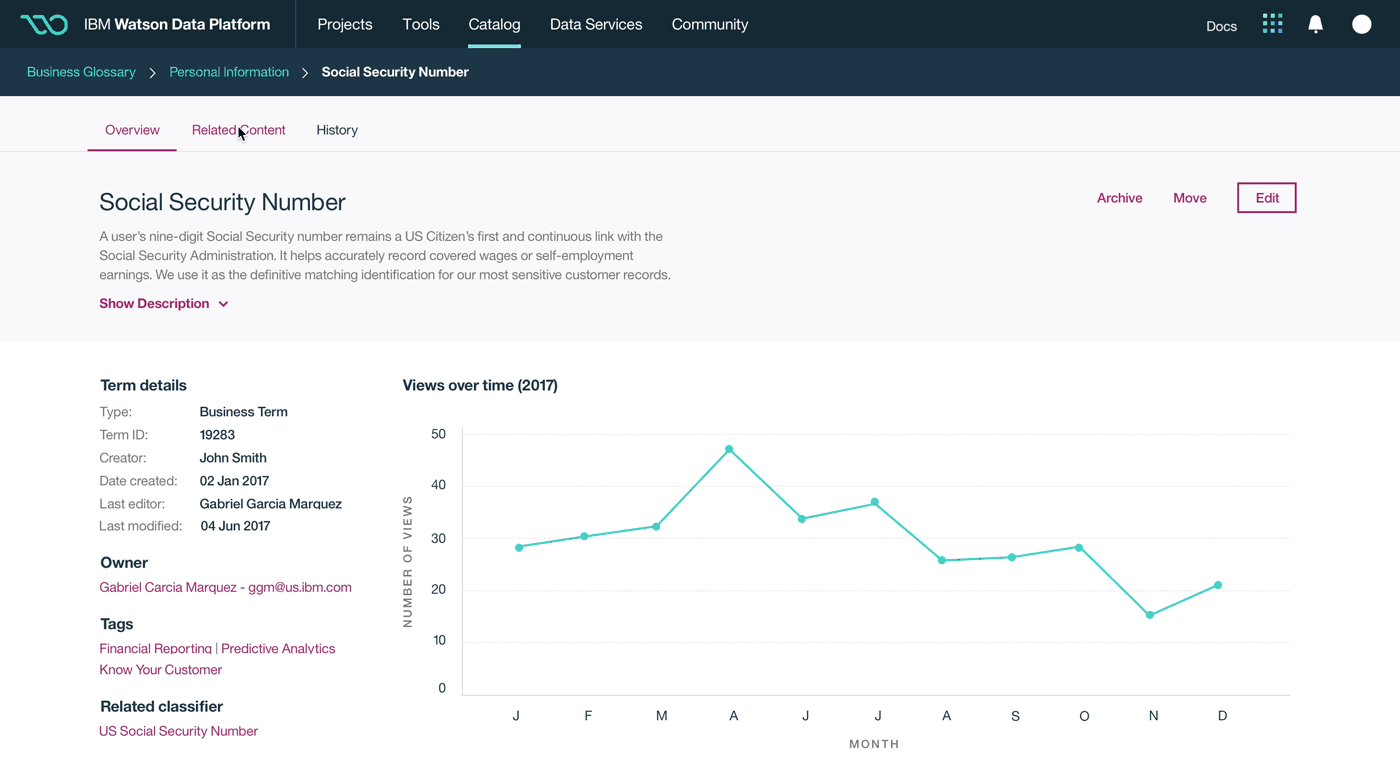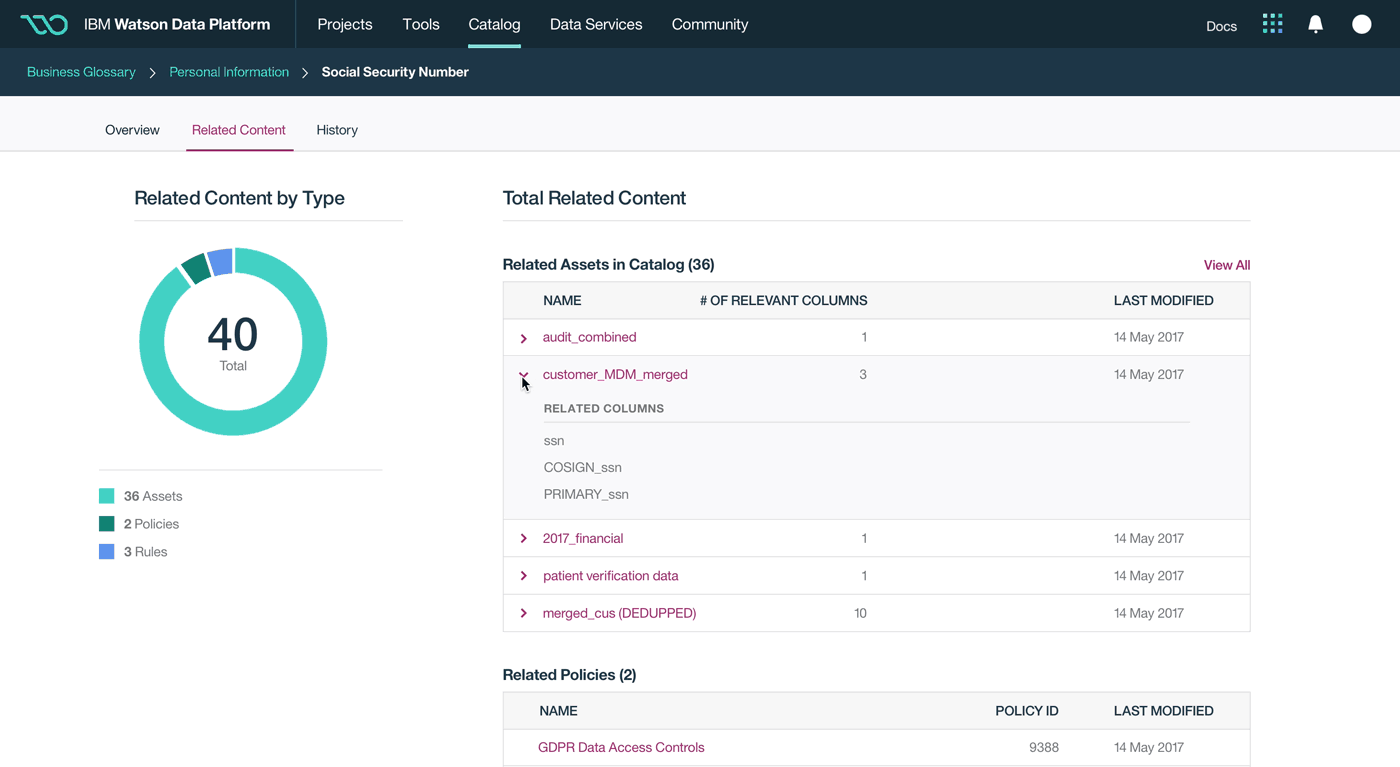
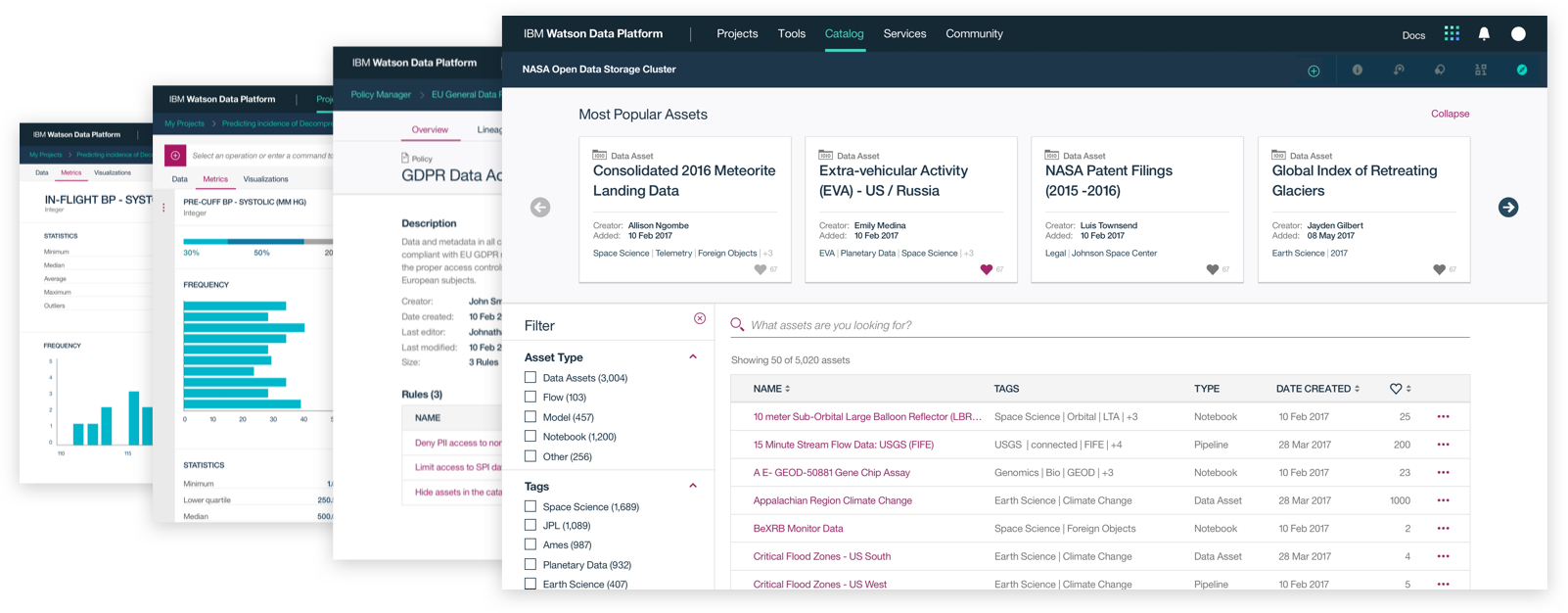
This was a large goal with many different problems to solve and vastly different users to solve for. Our team was broken down into squads that each tackled a different task data teams must complete. Over the course of a year, we designed experiences that enable data teams to discover, ingest, catalog, govern, and analyze information.
Here's a quick summary of the parts of the Watson Data Platform that were already taking shape before I joined the team: