IBM StoredIQ for Legal
Fall 2015 - Summer 2016
The Project
Introduction
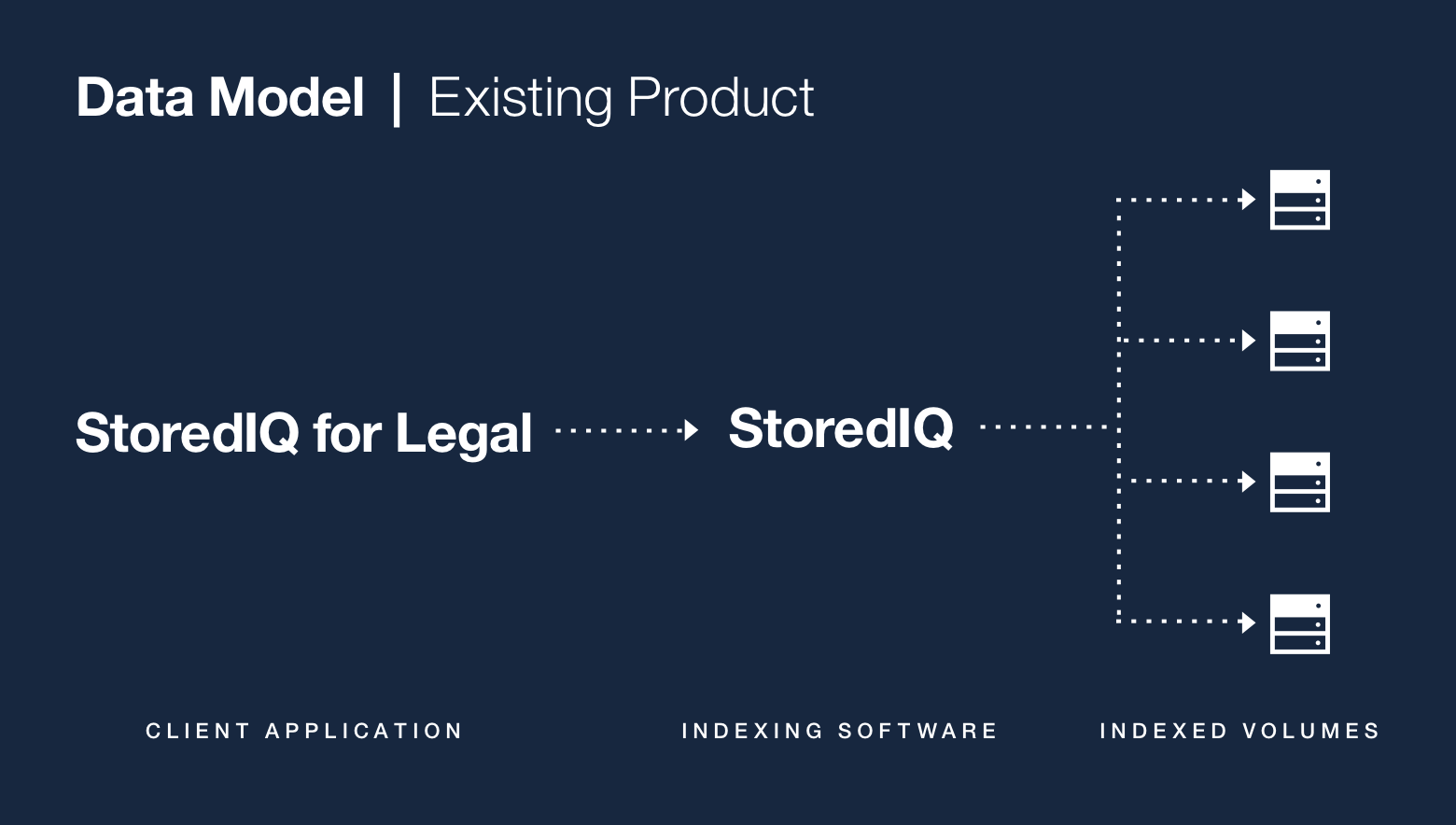
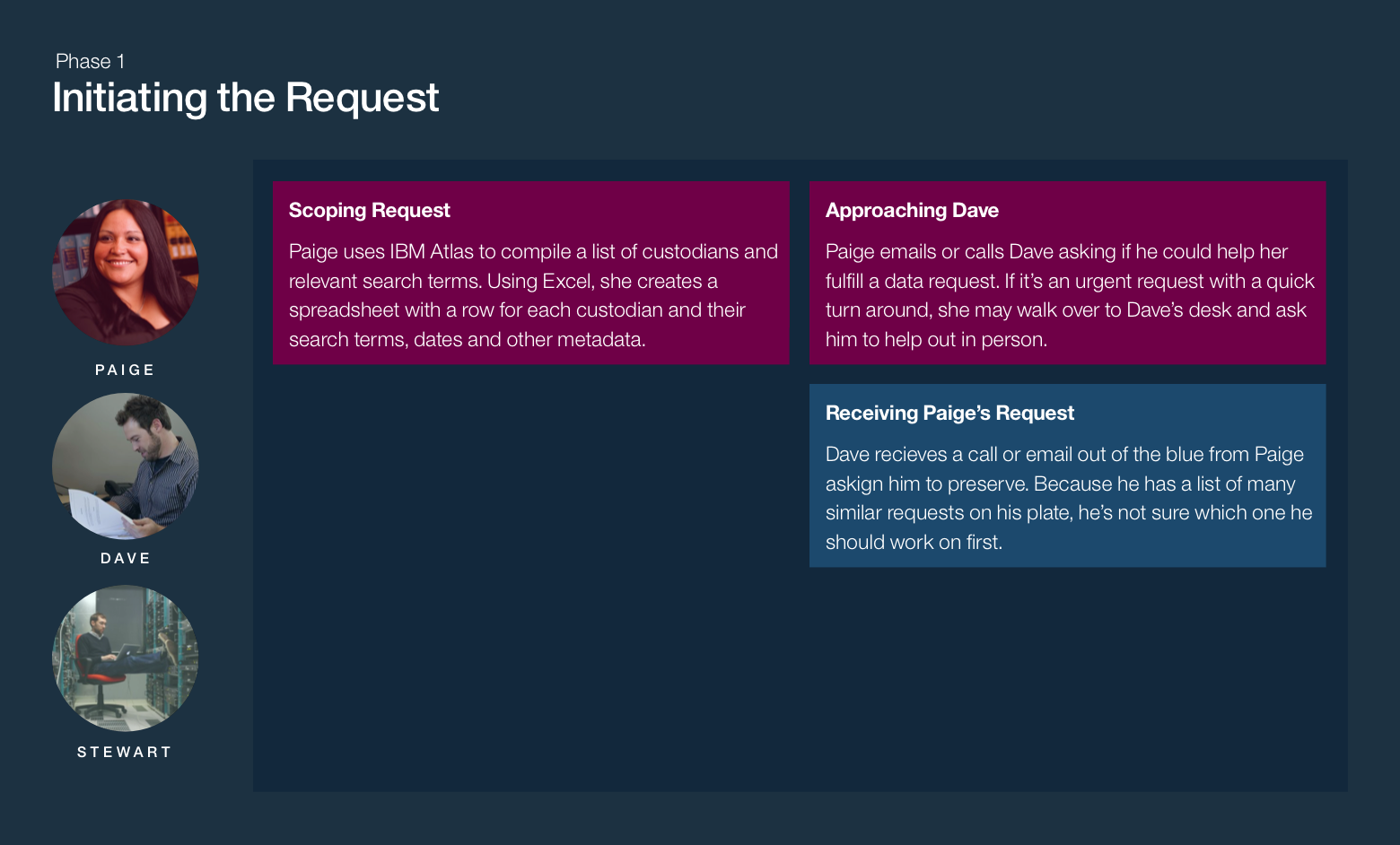
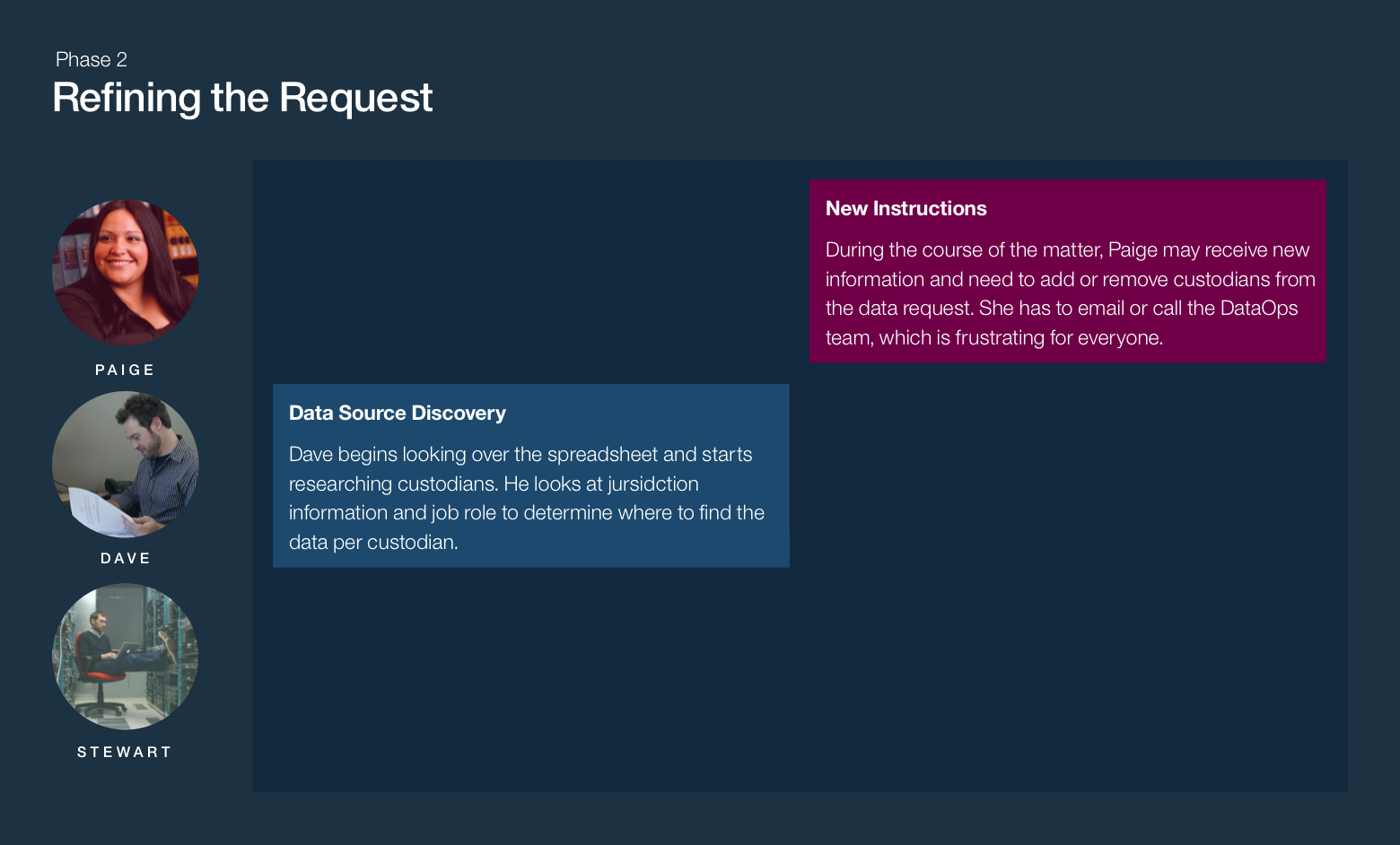
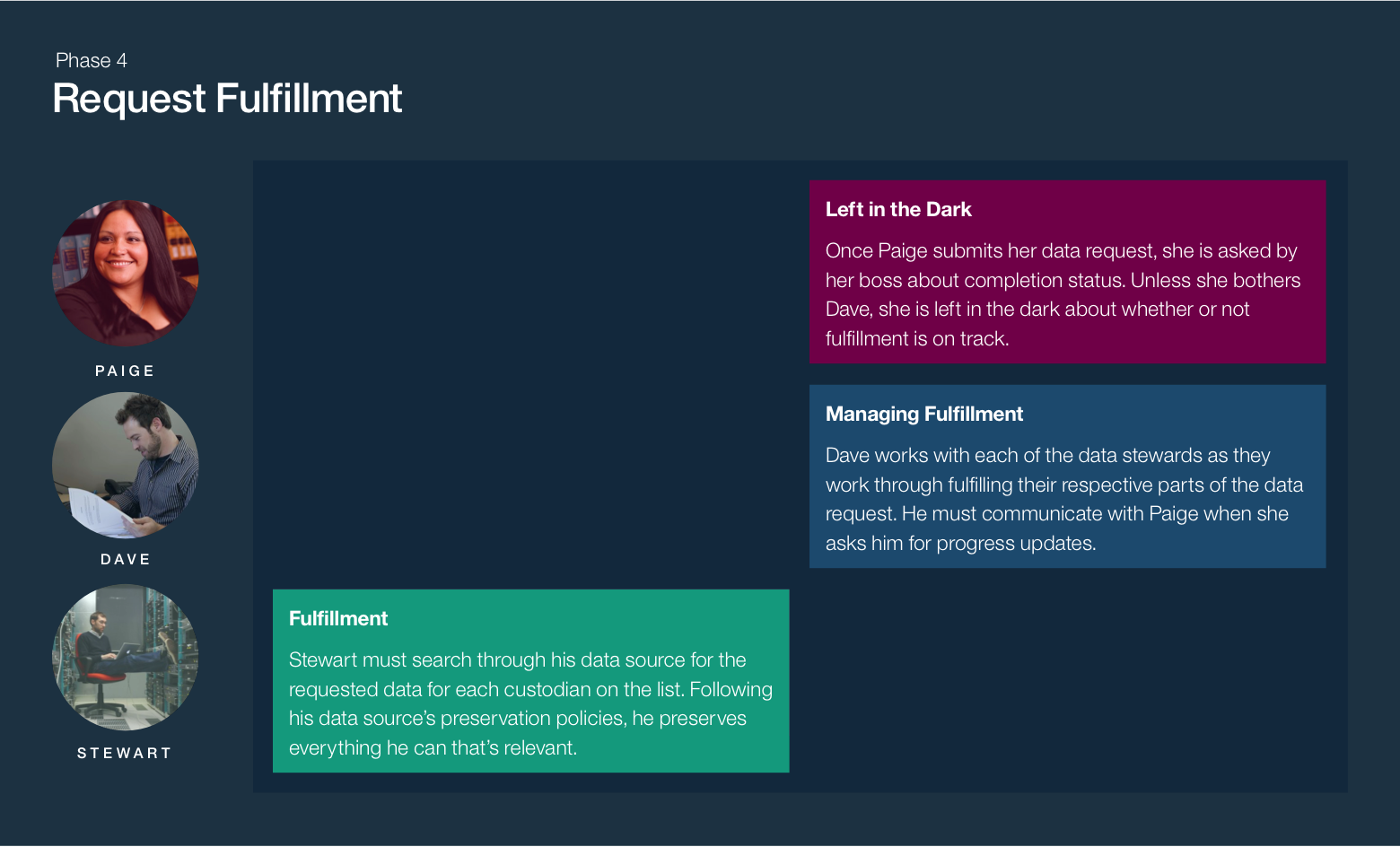
In November 2015, I joined the IBM Analytics Platform team to help build IBM StoredIQ for Legal, an electronic discovery tool designed to help legal staff and IT departments manage legal matters and respond to litigation.
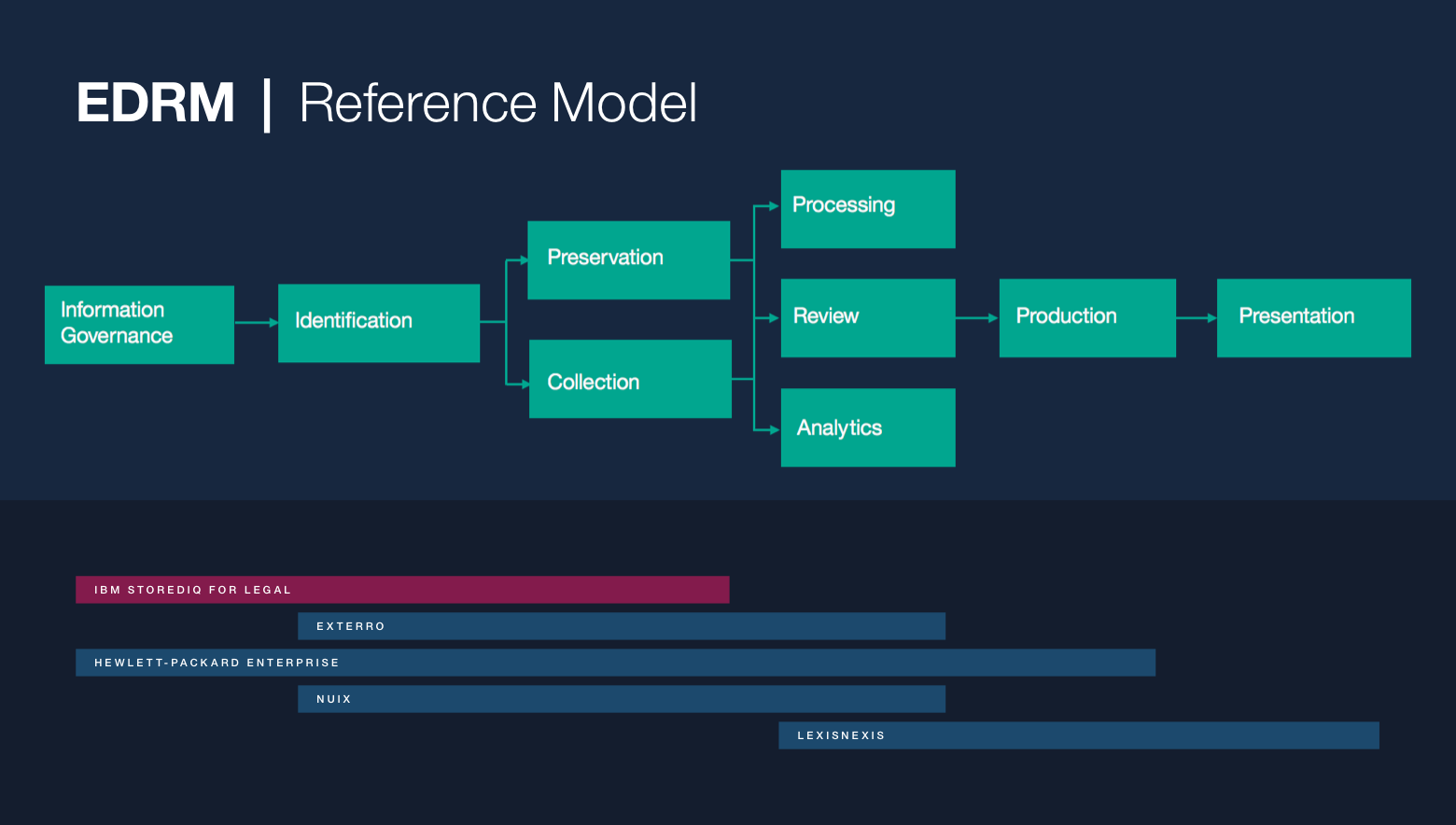
Discovery & Governance 101
Modern Fortune 500 companies produce an unfathomable amount of information every single day: everything from HR records and financial statements to cat GIFs posted to Slack. Consider the most common form of electronic data created by organizations: email. An average employee at a large company like IBM sends and receives around 50 emails on a normal work day. After just one year of service, this employee would have racked up 13,000 emails. This means that every year a company like IBM sends and receives about 5 billion emails! Storing this data, either on premise or in the cloud is one of the largest expenses most fortune 500 companies face.
While retaining this data is costly, when companies are involved in a lawsuit they must be able to produce evidence when requested. In fact, most industries require that companies retain data for a certain amount of time, regardless of the size.
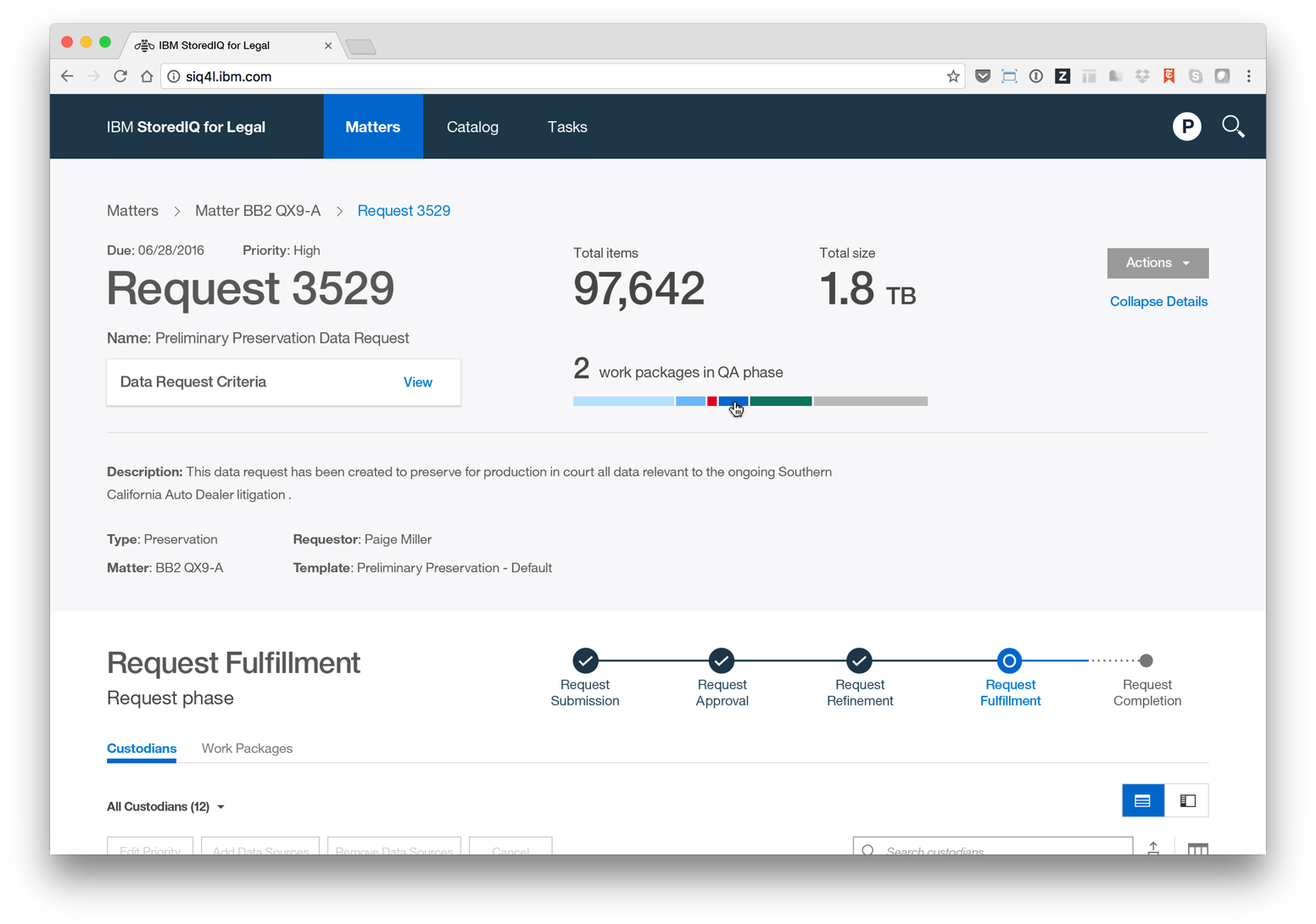
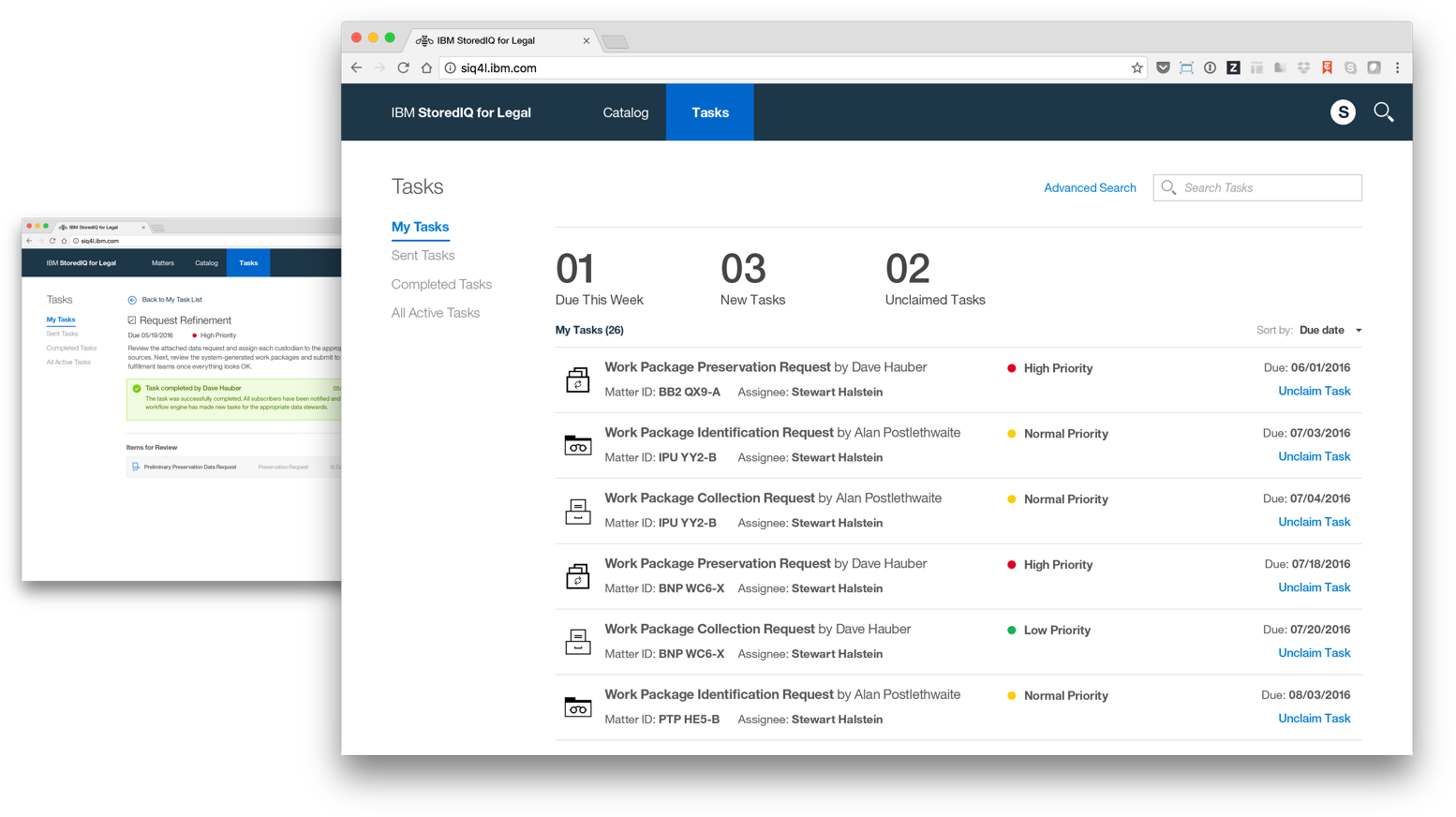
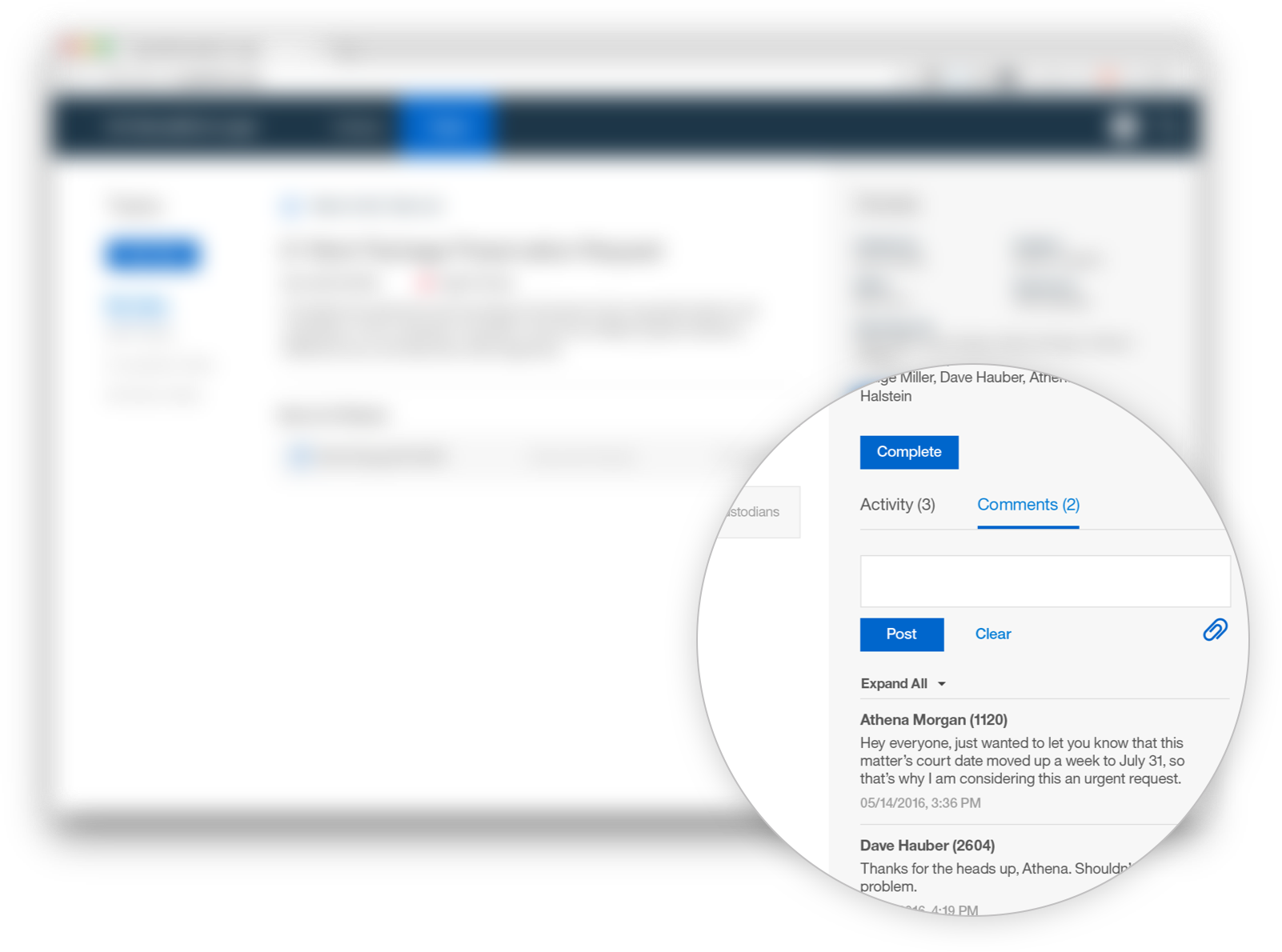
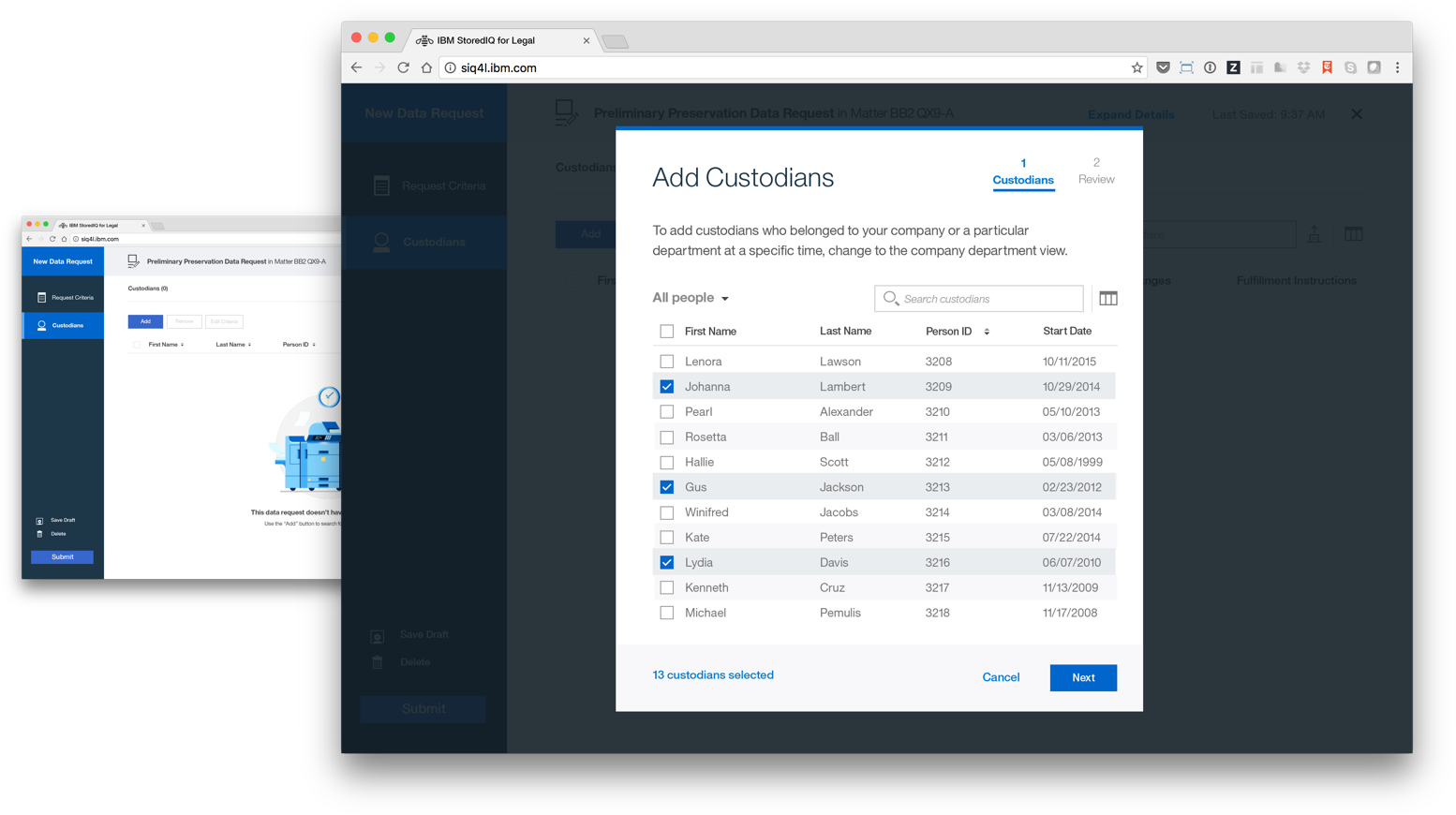
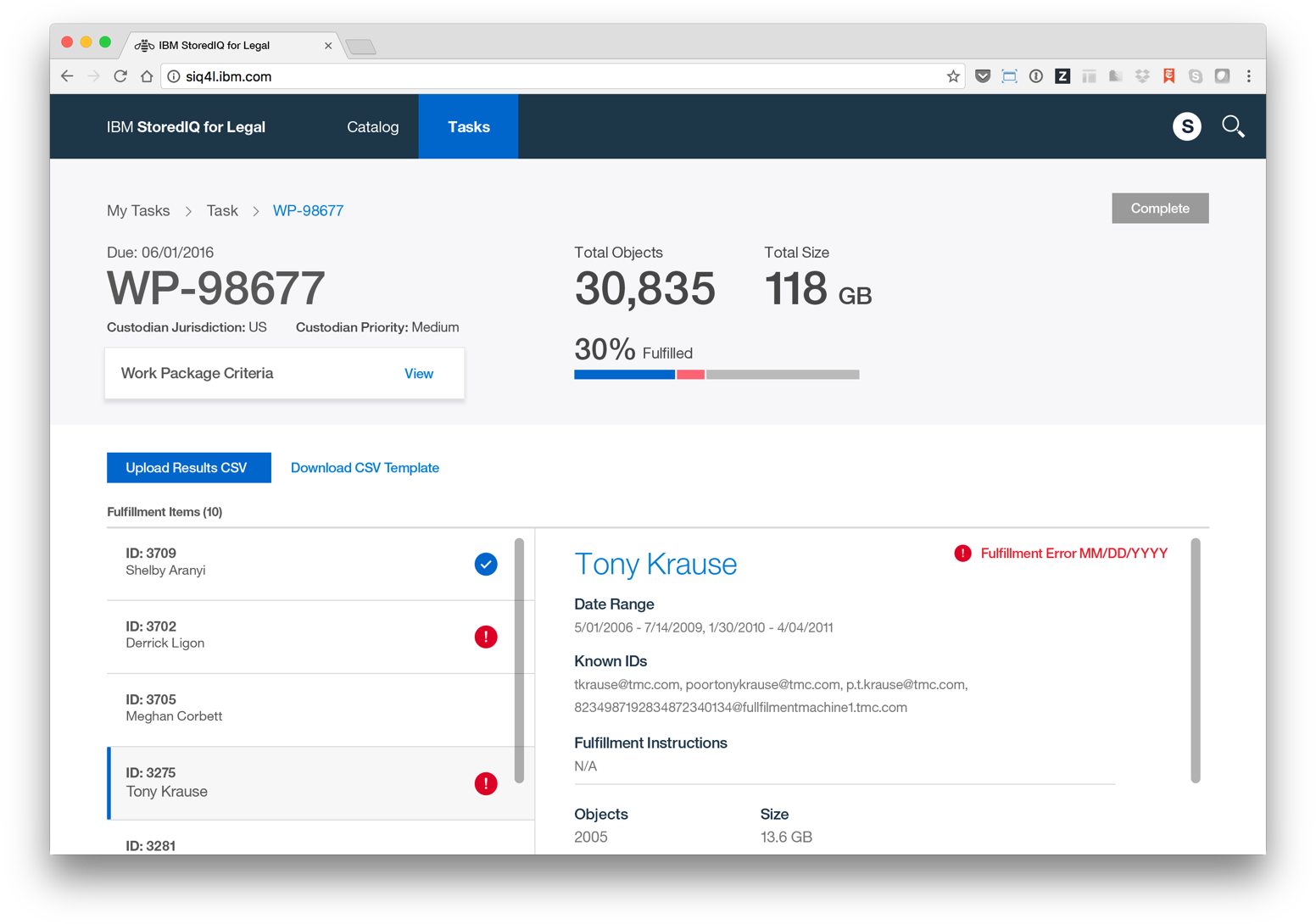
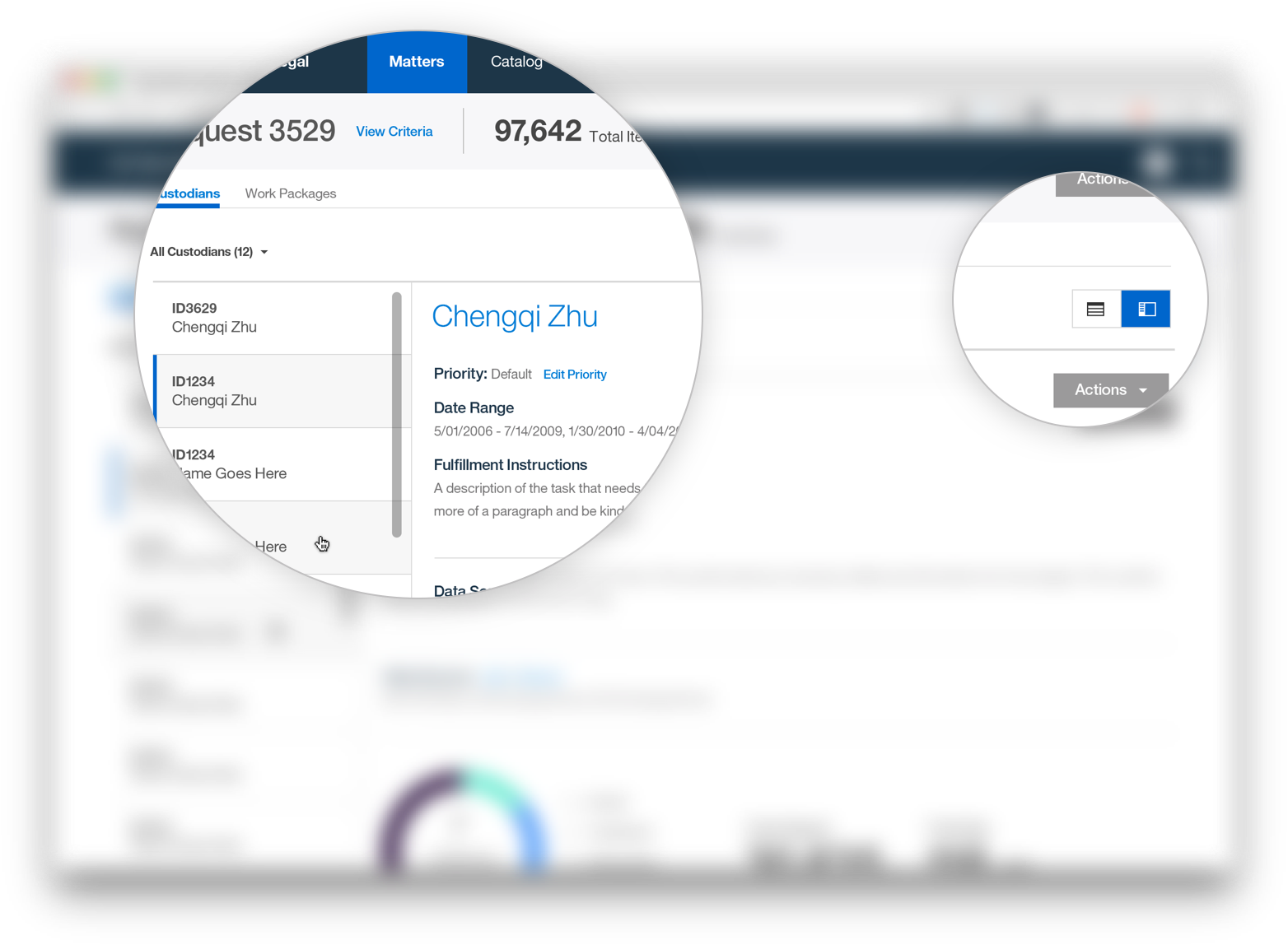
The focus of StoredIQ for Legal is to give paralegals, attorneys and IT staff the tools they need to discover and produce relevant information when they are facing impending litigation or an internal investigation.
My Role
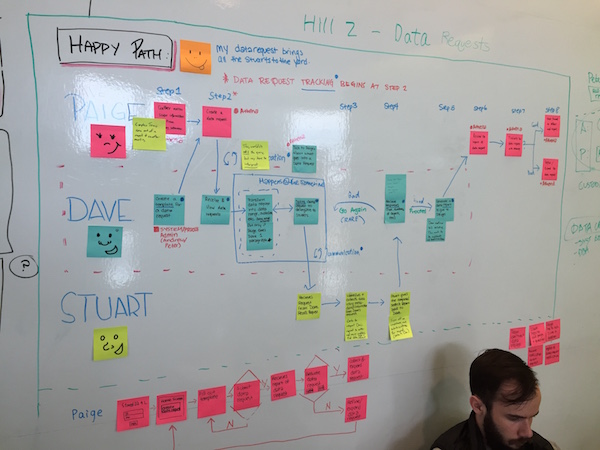
I joined the team immediately after the second release launched and was able to participate in the kickoff planning workshop for the third release. As this was my first time working on an IBM release from initial research to the delivery of a final product, I was incredibly excited and nervous to learn all about the nitty gritty details involved in shipping something at this scale. It was really helpful to have an insanely talented group of collaborators to lean on and grow with throughout this release.